

Was ist das tidyverse?
Das tidyverse ist eine Sammlung von R-Paketen, die alle auf der selben „tidy“ Logik basieren und dieselbe Code-Schreibweise nutzen. Der Code von tidyverse ist sehr gut lesbar: Man kann den Code in der Regel laut vorlesen und versteht, was er tut.
Das tidyverse wurde 2019 von Hadley Wickham und Kolleg:innen entwickelt und macht seitdem die Arbeit mit Daten viel einfacher. Es unterstützt bei der Datenmanipulation, Datenvisualisierung und Datenanalyse. Alle tidyverse-Packages sind kompatibel und gleichen sich in ihrer Logik. Das tidyverse ist benutzerfreundlich, De-facto-Standard für das Datenmanagement in R und ziemlich nützlich.
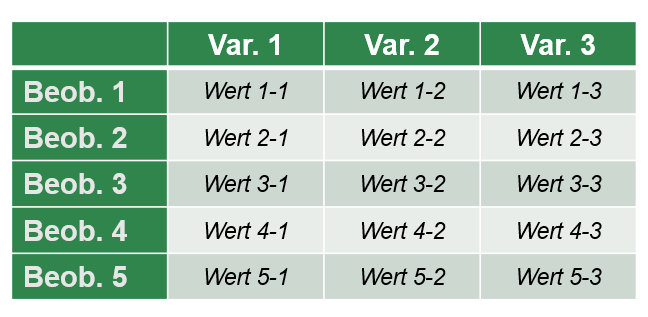
Das tidyverse basiert auf einer Reihe von Prinzipien und einer Syntax (=Regeln der Programmsprache, ähnlich der Grammatik), die die Bedeutung von den namensgebenden tidy data (=aufgeräumten Daten) hervorheben, d. h. Daten, die in Spalten, Zeilen und Zellen organisiert sind.
Tidy data zeichnet sich dadurch aus, dass
- …jede Variable in einer Spalte steht.
- …jede Beobachtung, das heißt jeder Fall, in einer Zeile steht.
- …jeder Wert eine eigene Zelle hat.
Packages im tidyverse
Zuerst können die Daten mit dem readr-Package aus dem tidyverse importiert werden.
Das tidyr-Package hilft anschließend die Daten in eine aufgeräumte Form (vgl. tidy data) zu bringen, um den Rest der Analyse zu erleichtern.
Die Datentransformation wird durch das dplyr-Package angenehmer. dplyr ist auf den sogenannten Pipe-Operator (%>%) angewiesen. Mit dem %>%-Operator können Funktionen aneinandergehängt und auf dasselbe Quellobjekt angewendet werden. Das ermöglicht ein schrittweises Vorgehen und beugt Verschachtlung vor. Da der %>%-Operator oft gebraucht wird kann mit den Shortcuts Strg + Shift + M (Windows) bzw. Cmd. + Shift + M (Mac) viel Zeit gespart werden.
Eng mit dem dplyr-Package sind vier weitere Packages verbunden, die jeweils Werkzeuge für bestimmte Spaltentypen bereitstellen:
- stringr für Zeichenfolgen.
- forcats für Faktoren (kategorialer Datentyp).
- lubridate für Datums- und Uhrzeitangaben.
- hms für Uhrzeiten.
Nach der Datentransformation macht das ggplot2-Package die Datenvisualisierung schön und einfach möglich.
Einen schönen Überblick über die im tidyverse inkludierten Packages, Erklärungen davon und in vielen Fällen auch hilfreiche Cheatsheets, gibt es auch auf der tidyverse-Webseite.
Literatur
Wickham et al. (2019). Welcome to the tidyverse. Journal of Open Source Software, 4(43), 1686. https://doi.org/10.21105/joss.01686