In R gibt es verschiedene Datentypen, die auf unterschiedliche Weise verwendet werden können, um Daten effektiv zu analysieren und zu verarbeiten. Diese Datentypen bestimmen, welche Art von Werten eine Variable speichern kann und welche Operationen darauf anwendbar sind. Zum Beispiel können nominalskalierte Variablen – wie sie bereits im Abschnitt über Skalenniveaus vorgestellt wurden – in verschiedenen Formen dargestellt werden: als Faktoren, Zeichenketten, Logicals oder sogar als Integers. Im Folgenden werden die grundlegenden Datentypen in R vorgestellt und anhand von Beispielen erläutert.
Zahlen
In R sind die Datentypen für Zahlen in zwei Hauptkategorien unterteilt: integer und numeric. Während integer speziell für Ganzzahlen ohne Dezimalstellen steht, ist numeric ein übergeordneter Typ, der sowohl Ganzzahlen als auch Gleitkommazahlen (Doubles) umfasst. In R bedeutet dies, dass jede als integer definierte Zahl automatisch als numeric angesehen wird, da numeric die umfassendere Kategorie darstellt.
Nach dem Laden des WoJ-Datensatzes aus dem tidycomm-Package prüfen wir mit der Funktion is.numeric(), ob die Variable autonomy_emphasis als numerischer Datentyp gespeichert ist.
Befehl:
# Laden des WoJ Datensatzes
WoJ <- tidycomm::WoJ # Überprüfung, ob die Variable 'autonomy_emphasis' im Dataframe 'WoJ' numerisch ist
is.numeric(WoJ$autonomy_emphasis) # Gibt TRUE zurück, wenn es ein numeric-Typ ist (double
oder integer)Ausgabe:
## [1] TRUEDie Bestätigung durch TRUE zeigt uns, dass autonomy_emphasis numerische Daten beinhaltet. Sollte die Variable fälschlicherweise nicht als numerisch eingelesen worden sein, würde R mit FALSE antworten. Weiterhin prüfen wir mit der Funktion is.integer(), ob die Daten spezifisch als Ganzzahlen gespeichert sind.
Befehl:
# Überprüfung, ob die Variable 'autonomy_emphasis' als Integer gespeichert ist
is.integer(WoJ$autonomy_emphasis) # Gibt TRUE zurück, wenn es ein reiner Integer-Typ istAusgabe:
## [1] FALSEDa hier FALSE zurückgegeben wird, bedeutet es, dass autonomy_emphasis, obwohl numerisch, nicht als integer gespeichert ist. Dies ist ein wichtiger Aspekt für die weitere Datenanalyse, da bestimmte Funktionen und Berechnungen spezifische Datentypen erfordern.
Um einen umfassenden Einblick in die Struktur und den spezifischen Datentyp der Variable zu erhalten, können wir auch den Befehl str() verwenden. Dieser Befehl ist besonders nützlich, um detaillierte Informationen über die Zusammensetzung eines Objekts in R zu erhalten, ohne spezifische Typ-Überprüfungen durchführen zu müssen.
Befehl:
# Anzeige der Struktur von 'autonomy_emphasis' zur Überprüfung des genauen Datentyps
str(WoJ$autonomy_emphasis) # Zeigt den Typ der Daten in der Variable, z.B. int, num, etc.Ausgabe:
## num [1:1200] 4 4 4 5 4 4 4 3 5 4 ...Die Ausgabe[1:1200] zeigt zusätzlich, dass diese Variable 1200 Beobachtungen umfasst, mit den ersten Werten 4, 4, 4, 5, 4…
Text
In der Datenanalyse mit R ist das Verständnis des Datentyps jeder Variable wesentlich, da es bestimmt, welche Operationen möglich sind. Neben numerischen Datentypen, die für Berechnungen wie die Bestimmung von Durchschnitten oder Standardabweichungen verwendet werden, ist auch der Datentyp für Text wichtig. In R wird Text als Zeichenkette oder string bezeichnet und der spezifische Datentyp für diese strings heißt character, wobei einzelne Buchstaben und Symbole ebenfalls als character (kurz char) klassifiziert sind.
Um zu überprüfen, ob eine Variable als Text gespeichert ist, kann die Funktion is.character() genutzt werden. Beispielsweise lässt sich damit feststellen, ob die Variable employment im Datensatz WoJ als Text vorliegt.
Befehl:
# Überprüfung, ob die Variable 'employment' im Dataframe 'WoJ' als Text gespeichert ist
is.character(WoJ$employment) # Gibt TRUE zurück, wenn es ein Character-Typ istAusgabe:
## [1] TRUEWir können die Funktion auch auf ein benutzerdefiniertes Objekt anwenden. Hierzu definieren wir zunächst ein Objekt namens sentence, das den Textwert „Irgendwas mit Medien“ enthält. Anschließend geben wir den Inhalt von sentence mit der Funktion print() aus, um zu bestätigen, dass der Text korrekt gespeichert wurde.
Befehl:
# Definition des Objekts "sentence" mit einem Textwert
sentence <- "Irgendwas mit Medien"
# Ausgabe des Objekts "sentence"
print(sentence)Ausgabe:
## [1] "Irgendwas mit Medien"Danach überprüfen wir, ob das sentence tatsächlich als Text (character) in R gespeichert wurde.
Befehl:
# Überprüfung, ob "sentence" als Text eingelesen wurde
is.character(sentence) # Gibt TRUE zurück, wenn es ein Character-Typ istAusgabe:
## [1] TRUEEs wird bestätigt, dass unser Objekt sentence in R korrekt als Zeichenkette behandelt wird.
Ein bedeutender Unterschied zwischen den Datentypen Zahl und Text in R besteht darin, dass Textwerte in Anführungszeichen gesetzt werden, um diese als solche zu kennzeichnen. Dies stellt sicher, dass R sie nicht als numerische Werte interpretiert.
Befehl:
# Weist dem Objekt "word" einen Textwert zu
word <- "1"
is.numeric(word)Ausgabe:
## [1] FALSEIn diesem Beispiel wird der Variablen word der Wert „1“ zugewiesen, wobei die Anführungszeichen angeben, dass es sich um eine Zeichenkette handelt, nicht um eine Zahl. Die Funktion is.numeric(word) prüft, ob die Variable ein numerischer Datentyp ist. Da wir diese als Text definiert haben, gibt die Funktion FALSE zurück.
Wenn ein Objekt als Zahl verstanden werden soll, geben wir es ohne Anführungszeichen ein.
Befehl:
# Weist dem Objekt "word" eine Zahl zu
word <- 1
is.numeric(word)Ausgabe:
## [1] TRUEIn diesem Fall wird der Variablen der Wert ohne Anführungszeichen zugewiesen, was darauf hinweist, dass es sich um eine Zahl handelt. Die Funktion is.numeric(word) gibt TRUE zurück, was bestätigt, dass word jetzt ein numerischer Wert ist.
Faktoren
Faktoren sind speziell dafür entwickelt, kategoriale Daten zu verwalten, egal ob diese in Form von Zahlen oder Text vorliegen. Jeder Dateneintrag wird systematisch einer bestimmten Kategorie zugeordnet, sodass die Daten wie auf einer Skala behandelt werden können, die entweder nominal oder ordinal ist.
Beispielsweise kann die Variable employment in unserem Datensatz, die anfangs als Text gespeichert war, in einen Faktor umgewandelt werden, um die verschiedene Beschäftigungsarten effektiv zu klassifizieren.
Befehl:
# Umwandlung der Variable 'employment' von Text zu einem Faktor
WoJ$employment <- as.factor(WoJ$employment)
# Überprüfung, ob 'employment' ein Faktor ist
is.factor(WoJ$employment)Ausgabe:
## [1] TRUEAlternativ können wir auch die mutate()– Funktion aus dem dplyr – Package nutzen, um die Umwandlung von Datentypen innerhalb eines Dataframes effizient durchzuführen. Das gilt nicht nur für die Umwandlung von Text in Faktoren, sondern auch für andere Datentypänderungen, die in der Datenverarbeitung erforderlich sein könnten.
Befehl:
# Installieren des dplyr Pakets - nur das erste Mal erforderlich
# install.packages("dplyr")
# Laden des dplyr Pakets
library(dplyr)
# Umwandlung von 'employment' zu einem Faktor mit mutate()
WoJ <- WoJ %>%
mutate(employment = as.factor(employment))
# Überprüfung, ob 'employment' ein Faktor ist, nach der Umwandlung mit mutate()
is.factor(WoJ$employment)Ausgabe:
## [1] TRUENachdem die Variable employment als Faktor definiert wurde, können wir die verschiedenen Kategorien dieses Faktors mit der Funktion levels() abfragen. Dies zeigt uns alle einzigartigen Beschäftigungsstatusse, die in den Daten vorkommen.
Befehl:
# Anzeigen der verschiedenen levels des Faktors 'employment'
levels(WoJ$employment)Ausgabe:
## [1] "Freelancer" "Full-time" "Part-time" Fehlende Daten
Fehlende Daten sind ein häufiges Problem in Datensätzen und können die Analyse und Interpretation beeinträchtigen. In R können fehlende Daten (NAs) mithilfe des Befehls is.na() überprüft werden. Dieser Befehl gibt TRUE zurück, wenn ein Wert in einer Variablen fehlt, und FALSE, wenn er vorhanden ist.
Befehl:
# Überprüfung auf fehlende Daten in der Variable 'temp_contract'
is.na(WoJ$temp_contract) # Gibt TRUE zurück, wenn es NA-Werte in der Variable gibtAusgabe:
## [1] FALSE FALSE FALSE FALSE FALSE TRUE FALSE FALSE FALSE FALSE FALSE TRUE FALSE ...Manchmal können Datensätze sehr umfangreich sein, was es schwierig macht, den Überblick zu behalten. In solchen Fällen können wir mithilfe von sum() und is.na() die Gesamtanzahl der fehlenden Werte in einer Variable ermitteln.
Befehl:
# Anzahl der fehlenden Daten in der Variable 'temp_contract'
sum(is.na(WoJ$temp_contract)) # Gibt die Anzahl der NA-Werte in der Variable zurückAusgabe:
## [1] 199Logische/andere Operatoren
Logische Operatoren (logicals) in R ermöglichen das Definieren spezifischer Bedingungen und das Filtern von Daten, geeignet für komplexe Datenmanipulationen und das Extrahieren gezielter Informationen aus großen Datensätzen. Diese Operatoren bewerten Bedingungen und liefern Ergebnisse, die entweder wahr (TRUE) oder falsch (FALSE) sind.
| Operator | Beschreibung | Beispiel |
|---|---|---|
| NA | Steht für fehlende Daten. | is.na(WoJ$temp_contract) findet fehlende Vertragsdaten in unserem Datensatz. |
| TRUE | Zeigt an, dass eine Bedingung wahr ist. | WoJ$employment == „Full-time“ gibt TRUE für Einträge zurück, die Vollzeitbeschäftigung angeben. |
| FALSE | Zeigt an, dass eine Bedingung falsch ist. | WoJ$employment != „Full-time“ gibt FALSE für Einträge zurück, die keine Vollzeitbeschäftigung angeben. |
| & | Verknüpft zwei Bedingungen, beide müssen wahr sein (logisches UND). | WoJ$work_experience > 5 & WoJ$country == „Germany“ findet Einträge, die sowohl mehr als 5 Jahre Erfahrung als auch den Standort Deutschland haben. |
| | | Verknüpft zwei Bedingungen, eine davon muss wahr sein (logisches ODER). | WoJ$work_experience < 5 | WoJ$country != „Germany“ findet Einträge, die weniger als 5 Jahre Erfahrung haben oder nicht in Deutschland sind. |
| == | Prüft, ob zwei Werte gleich sind. | WoJ$country == „Germany“ findet Einträge, die explizit „Germany“ als Land angeben. |
| != | Prüft, ob zwei Werte ungleich sind. | WoJ$country != „Germany“ findet Einträge, die nicht „Germany“ als Land angeben. |
| > | Prüft, ob ein Wert größer als der andere ist. | WoJ$work_experience > 10 findet Einträge mit mehr als 10 Jahren Arbeitserfahrung. |
| < | Prüft, ob ein Wert kleiner als der andere ist. | WoJ$work_experience < 15 indet Einträge mit weniger als 15 Jahren Arbeitserfahrung. |
| >= | Prüft, ob ein Wert größer oder gleich dem anderen ist. | WoJ$trust_government >= 3 findet Einträge, bei denen das Vertrauen in die Regierung 3 oder höher ist. |
| <= | Prüft, ob ein Wert kleiner oder gleich dem anderen ist. | WoJ$trust_government <= 2 findet Einträge, bei denen das Vertrauen in die Regierung 2 oder niedriger ist. |
Schauen wir uns an, wie das in R tatsächlich umgesetzt wird. Angenommen, wir möchten einen Datensatz erstellen, der nur Teilnehmer mit mehr als 7 Jahren Berufserfahrung enthält.
Befehl:
# Erzeugen eines Subsets von 'WoJ', das nur Teilnehmer mit mehr als 7 Jahren Berufserfahrung enthält
WoJ_subset <- WoJ[WoJ$work_experience > 7,]
# Anzeigen der Struktur des gefilterten Dataframes 'WoJ_subset'
str(WoJ_subset)Ausgabe:
## tibble [949 × 15] (S3: tbl_df/tbl/data.frame)
## $ country : Factor w/ 5 levels "Austria","Denmark",..: 3 1 4 3 2 4 1 2 5 1 ...
## $ reach : Factor w/ 4 levels "Local","Regional",..: 3 3 1 1 3 1 1 3 2 3 ...
## $ employment : Factor w/ 3 levels "Freelancer","Full-time",..: 2 3 1 2 2 2 2 1 2 2 ...
## $ temp_contract : Factor w/ 2 levels "Permanent","Temporary": 1 1 NA 1 1 1 1 NA 1 1 ...
## $ autonomy_selection: num [1:949] 5 4 4 4 3 5 5 4 3 3 ...
## $ autonomy_emphasis : int [1:949] 4 4 4 4 3 5 5 4 4 3 ...
## $ ethics_1 : num [1:949] 2 2 2 1 2 1 1 2 1 1 ...
## $ ethics_2 : num [1:949] 3 3 4 3 4 2 1 4 2 4 ...
## $ ethics_3 : num [1:949] 2 2 4 2 4 1 2 2 4 4 ...
## $ ethics_4 : num [1:949] 1 1 3 2 4 3 1 4 2 4 ...
## $ work_experience : num [1:949] 10 15 27 24 11 25 8 25 10 23 ...
## $ trust_parliament : num [1:949] 3 3 4 2 4 1 3 3 3 3 ...
## $ trust_government : num [1:949] 3 2 4 1 3 1 2 3 2 2 ...
## $ trust_parties : num [1:949] 3 2 3 3 3 1 2 3 2 2 ...
## $ trust_politicians : num [1:949] 3 2 2 2 3 1 2 3 2 1 ...
Nach dem Filtern enthält der neue Datensatz WoJ_subset nur noch 949 Beobachtungen, da nur Personen mit mehr als 7 Jahren Berufserfahrung selektiert wurden.
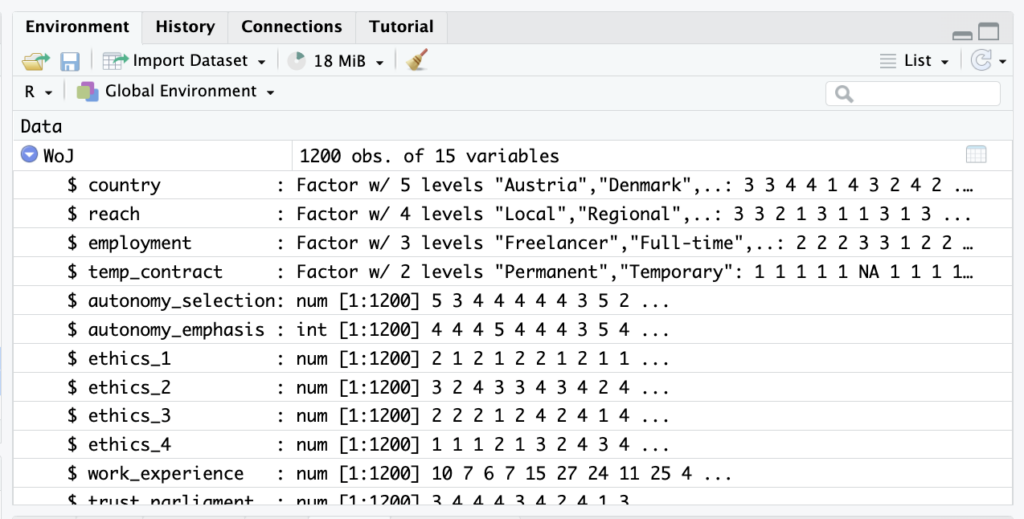
Hilfreicher Tipp: Überprüfung von Datentypen im Environment
RStudio bietet eine sehr benutzerfreundliche Oberfläche, um die Datentypen der Variablen in einem Datensatz zu erkennen. In der Environment-Ansicht werden alle Objekte aufgelistet, die aktuell im Arbeitsbereich vorhanden sind. Neben jedem Objektnamen ist eine kurze Beschreibung des Datentyps und der Datenstruktur zu sehen. Zum Beispiel zeigt es num für numerische Daten oder Factor für Faktoren, zusammen mit der Anzahl der Beobachtungen und aller Variablen (z. B. 1200 obs. of 15 variables):