
Gerade bei größeren Datensätzen, wie sie in der Kommunikationswissenschaft fast immer vorliegen, ist es sehr unpraktisch alle Werte manuell in R einzugeben. Die erste relevante Frage lautet folglich: Wie bekommt man die Daten, die auf dem lokalen Computer gespeichert sind in R?
1 Working Directory
1.1 Working Directory einfach setzen
Man könnte die Daten über das R-Kontextmenü importieren, aber es gibt auch einen eleganteren Weg. Damit zeigt man R, wo auf dem Computer ein Datensatz liegt. Die Adresse, man spricht von dem Working Directory, ist der Ordnerpfad zu dem Ordner, in dem die Daten gespeichert sind.
Um diese Adresse abzurufen, wird navigiert…
Windows:
auf diesen Ordner und öffnet ihn. In der Navigationszeile ist jetzt die Adresse angegeben, jedoch noch nicht in dem Format, welches benötigt wird.
Um das passende Format anzuzeigen und anschließend zu kopieren, muss das Ordnersymbol mit einem Linksklick angewählt werden (roter Kasten: ganz links oben in der Navigationszeile).

Jetzt wird die Adresse angezeigt, die meist so lautet: „C:\Users………“.

Die Adresse kopiert man in das Source Fenster von RStudio. Jetzt müssen nur noch die Rückstriche „\“ gegen Schrägstriche „/“ manuell ausgetauscht werden. Man erhält „C:/Users/…/…/…“.
Mac:
zu einem Dokument in dem Ordner, in welchem der Datensatz liegt und wählt die Datei mit zwei Fingern an, dann öffnet sich ein Fenster und man wählt „Informationen“ aus. Es öffnet sich ein Optionsmenü und man kann direkt den fertigen Ordnerpfad (roter Kasten) in das Source Fenster von RStudio kopieren (in RStudio erscheint dann auch die Adresse in der richtigen Form):
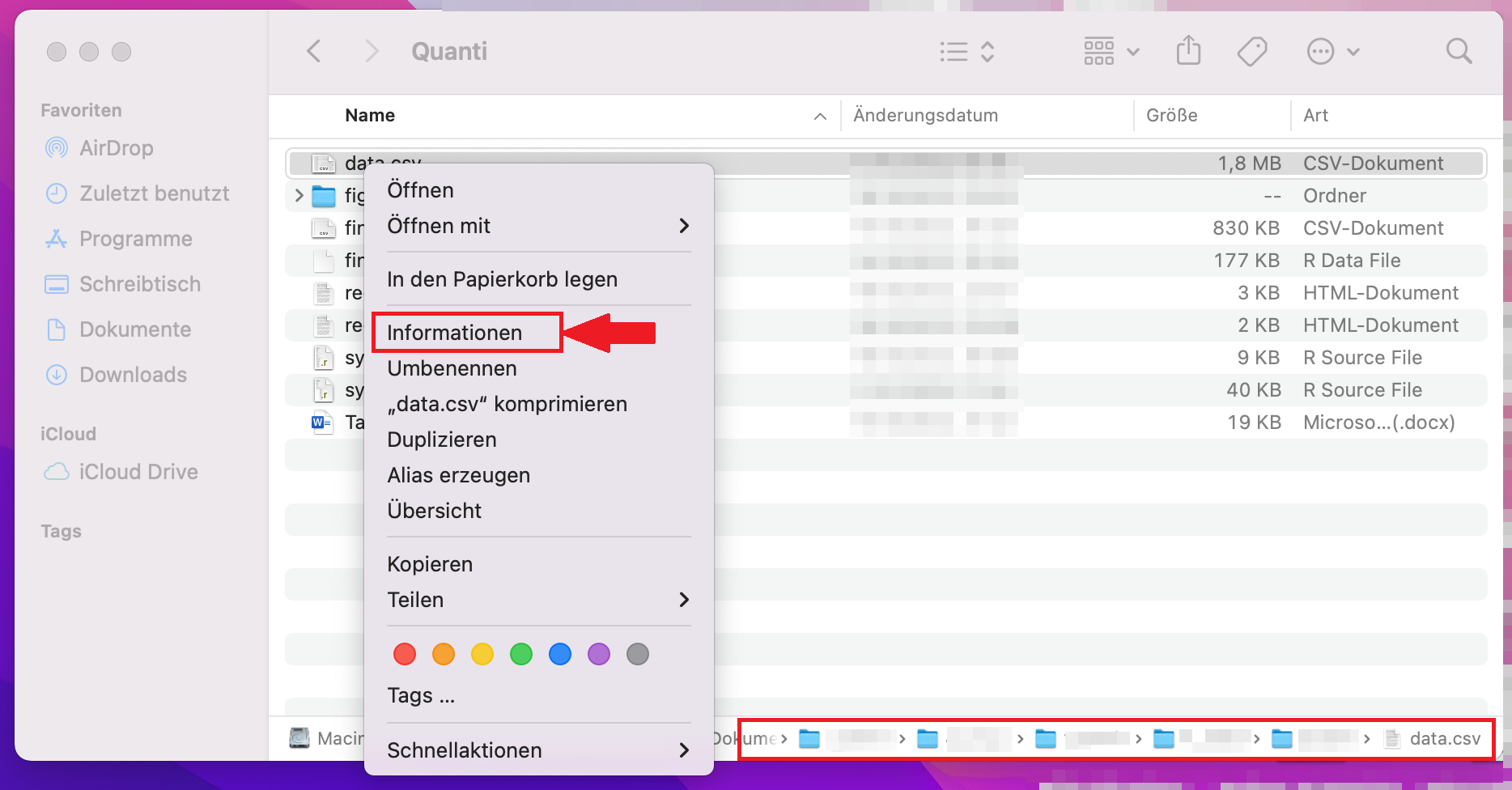
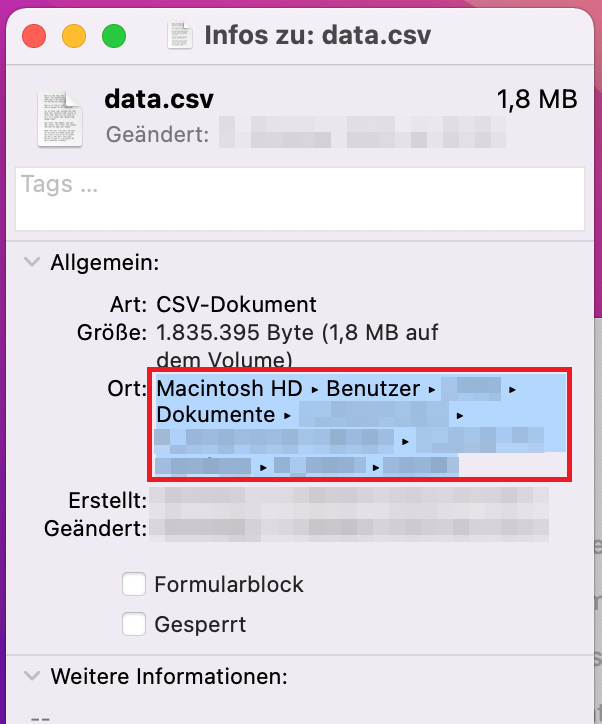
Die Adresse lautet meist so: „/Users/…/…/…“. Möglicherweise muss man auch den Schrägstrich „/“ am Anfang hinzufügen.
Jetzt hat man das Working Directory gefunden. Mit der Funktion setwd() (Abkürzung von „set working directory“) setzt man das Working Directory in R ein.
Wichtig: Die Art und Weise, wie das Working Directory gesetzt wird, unterscheidet sich zwischen Windows- und Mac-Betriebssystemen.
Windows:
setwd("C:/Users/…/…/…")Mac:
setwd("/Users/…/…/…")Wichtig: Man sollte als Working Directory niemals den Desktop festlegen. Der Datensatz sollte immer in einem gesonderten Ordner gespeichert sein. Das Risiko wäre sonst hoch, dass Updates und das normale Nutzen des Computers, zu Fehlern in R führen und der Code nicht mehr funktioniert.
Mit dem Befehl getwd() gibt R auch Auskunft darüber, welcher Pfad das aktuelle Working Directory darstellt:
getwd()Die Console gibt dann aus:
> getwd()
[1] "C:/Users/…/…/…"Dieser Weg funktioniert und ist auch schon recht elegant. Man kann allerdings R auch Datensätze finden lassen, ohne manuell die Adresse zu kopieren.
1.2 Working Directory elegant setzen
Beim manuellen Kopieren (und beim Ändern von „\“ in „/“) können leicht Fehler passieren. Zudem funktioniert der Code nur auf dem eigenen Gerät und nur wenn der Ordner immer da bleibt, wo er ist. Werden beispielsweise Ordner zusammengefasst, um den Desktop aufzuräumen, funktioniert der Code nicht mehr. Teilt man den eigenen Code können ihn Kommiliton:innen oder forschende Kolleg:innen nicht mehr ausführen, ohne das Working Directory anzupassen: Andere haben natürlich auch andere Benutzernamen, führen das Skript von anderen Quelldateipfaden aus oder haben andere Ordnerstrukturen. Das Package rstudioapi hilft dabei, dieses Problem anzugehen. Es wird folgendermaßen installiert:
install.packages("rstudioapi") # nur beim ersten Mal ausführenNun speichert (in RStudio oben links auf File, dann auf Save as) man diese R-Skriptdatei z.B. als „pojectxy.R“ in dem Ordner, in dem auch unser Datensatz liegt. Anschließen wird die folgende Codezeile in das R-Skript kopiert und ausgeführt:
setwd(dirname(rstudioapi::getSourceEditorContext()$path))Indem die Funktion dirname() auf rstudioapi::getSourceEditorContext()$path angewendet wird, wird der Verzeichnispfad des derzeit aktiven R-Skripts extrahiert und an setwd() übergeben, um ihn als Working Directory festzulegen. Dieser Ansatz stellt auch sicher, dass das Working Directory auf den richtigen Ordner gesetzt wird, selbst wenn beispielsweise das R-Skript innerhalb von RStudio umbenannt oder verschoben wird. So kann auch ein ganzer Ordner geteilt werden und alle, die diesen Ordner herunterladen, können den Code ohne Änderungen ausführen.
Hinweis: Denken Sie daran, das R-Skript im gewünschten Ordner zu speichern, bevor Sie die Funktion setwd() ausführen, um sicherzustellen, dass das richtige Working Directory gespeichert wird.
Mit dem Befehl getwd() gibt R den Pfad des aktuellen Working Directorys aus:
getwd()Die Console gibt dann aus:
> getwd()
[1] "C:/Users/…/…/…"
2 Daten aus dem Working Directory importieren
Nachdem das Working Directory nun festgelegt wurde, kann der Datensatz von dem Ort, den das Working Directory angibt, importiert werden. Vor dem Importieren des Datensatzes sollte man wissen, in welcher Form die Daten vorliegen:
- Welche Daten stehen in den Zeilen?
- Welche Daten stehen in den Spalten?
- Was sind hier die Fälle und was die Variablen?
- Welche Variablen gibt es?
- Wie wurden die Variablen erfasst?
- In welchem Dateiformat liegt der Datensatz vor?
Wenn diese Fragen geklärt sind, können die Daten importiert werden. Dabei ist zunächst die letzte Frage am wichtigsten: In welchem Dateiformat liegt der Datensatz vor?
R bietet eine breite Palette von Funktionen und Paketen zum Importieren von Daten aus verschiedenen Dateiformaten wie CSV, Excel, JSON, SPSS und anderen. Häufig verwendete Dateiformate und wie entsprechende Datensätze importiert werden können, werden im Folgenden beschrieben.
2.1 CSV (Daten durch Komma getrennt)
Liegt der Datensatz als „.csv“ vor, muss kein neues Package installiert werden. Diese Funktion ist Teil der Grundausstattung von R. Bei durch Komma „,“ getrennten Daten werden die Daten mit read.csv() eingelesen. Wenn die Zeilen für Fälle stehen und die Spalten für die Variablen, muss man das Argument header = TRUE setzen, um R mitzuteilen, dass die erste Zeile Variablennamen und keine Datenpunkte enthält. Schließlich weist man den Datensatz einem Source-Objekt zu und benennt sie, beispielsweise mit data. Die Daten sind nun in diesem Objekt gespeichert.
data <- read.csv("namevomdatensatz.csv", header = TRUE)2.2 CSV (Daten durch Semikolon getrennt)
Bei durch Semikolon „;“ getrennten Daten wird die Funktion read.csv2() verwendet.
data <- read.csv2("namevomdatensatz.csv", header = TRUE)2.3 Excel
Liegt der Datensatz als „.xlsx“ vor, muss ist zuerst das readxl Package zu installieren und aktivieren.
install.packages("readxl") # nur beim ersten Mal ausführen
library(readxl)Schließlich weist man mit der Funktion read_excel den Datensatz einem Source-Objekt zu, hier bezeichnet als „data“.
data <- read_excel("namevomdatensatz.xlsx")Standardmäßig wird davon ausgegangen, dass die erste Zeile der Excel-Datei Spaltennamen enthält.
2.4 JSON
Liegt der Datensatz als „.json“ vor, ist das jsonlite Package zu installieren und aktivieren.
install.packages("jsonlite") # nur beim ersten Mal ausführen
library(jsonlite)Schließlich weist man mit der Funktion fromJSON den Datensatz einem Source-Objekt zu, hier bezeichnet als „data“.
data <- fromJSON("namevomdatensatz.json")2.5 SPSS
Liegt der Datensatz als „.sav“ vor, ist das haven Package zu installieren und aktivieren.
install.packages("haven") # nur beim ersten Mal ausführen
library(haven)Schließlich weist man mit der Funktion read_spss den Datensatz einem Source-Objekt zu, hier bezeichnet als „data“.
data <- read_spss("namevomdatensatz.sav")Standardmäßig wandelt die Funktion read_spss() benutzerdefinierte Fehlstellen in NA um (d. h. Fehlstellen in R). Wenn Variablen mit benutzerdefinierten Fehlstellen in R eingelesen werden sollen (z. B. -9 beibehalten, anstatt alles in NA umzuwandeln), wird das Argument user_na verwenden:
data <- read_spss("namevomdatensatz.sav", user_na = TRUE)read_spss liest alle gekennzeichneten Variablen als Objekttyp (d. h. Klasse) namens haven_labelled ein, der die Kennzeichnungsinformationen speichert. Man kann die Label-Informationen mit einem Klick auf den blauen Pfeil neben dem Source-Objekt data im Environment-Fenster überprüfen (standardmäßig: rechte Seite von RStudio).
3 Navigieren im Datensatz
3.1 Variablen
Die Variablen im Datensatz sind alle in einem „Container“ gespeichert – dem Source-Objekt.
Diese Container für Variablen werden in R als data frames bezeichnet.
Um auf Variablen (die Spalten) zuzugreifen, welche Teil eines data frames sind, wird der Name des Source-Objekts mit dem Variablennamen durch den Zugriffsoperator $ kombiniert:
data$variablenameXYDieser Befehl gibt die Variablenwerte als Vektor aus.
Alternativ dazu kann auch die Spalte der Variable mit dem Namen variablenameXY mit einem klassischen base-R-Befehl angesteuert werden. Wenn die Variable in der fünften Spalte des data frames gespeichert ist, greift folgender Befehl auf die Variable zu:
data[5]Dieser Befehl gibt die Variablenwerte als data-frame-Objekt mit nur einer Spalte aus. Dadurch bleibt die Spaltenüberschrift “ variablenameXY“ intakt.
Wenn man einen Vektor über den Spaltenindex abrufen möchte, sind zwei Indizes angeben: Einen für die Zeile, die man auswählen möchte, gefolgt von einem Komma, und einen für die Spalte. Die Form ist dabei Variablenname[,Spaltennummer]. Da in dem Beispiel alle Zeilen, aber nur die Spalte 5 ausgewählt werden soll, bleibt die erste Position innerhalb der eckigen Klammern – also die Zeilennummer – leer:
Data[,5]3.2 Fälle
Um auf Fälle (=die Zeilen) zuzugreifen, kann ebenfalls dieser base-R-Befehl genutzt werden.
Wenn ein Fall über den Zeilenindex abgerufen werden soll, muss man zwei Indizes angeben: Einen für die Zeile, die man auswählen möchte, gefolgt von einem Komma, und einen für die Spalte. Die Form ist also Variablenname[Zeilennummer,]. Da in dem Da in dem Beispiel alle Spalten, aber nur die Zeile 9 ausgewählt werden soll, bleibt die erste Position innerhalb der eckigen Klammern – also die Spaltennummer – leer:
Data[9,]3.3 Beobachtungen
Um auf einzelne Beobachtungen (=die Zellen) zuzugreifen, ist das Vorgehen ähnlich.
data$variablenameXY[9]Dieser Befehl wählt erst, wie oben, die Spalte mit dem Namen variablenameXY aus und dann die Zeile 9.
Einzelne Zellen auszuwählen, ist auch mit der Indizierung aus Base-R möglich. Um eine Beobachtung über den Zeilenindex abzurufen, werden zwei Indizes angegeben: Einen für die Zeile, die man auswählen möchte, gefolgt von einem Komma, und einen für die Spalte. Die Form ist also Variablenname[Zeilennummer,Spaltennummer]. Wir wählen die Zelle in Zeile 9 und Spalte 5 mit folgendem Befehl aus:
data[9,5]