
Einführung
Einführung und Definition
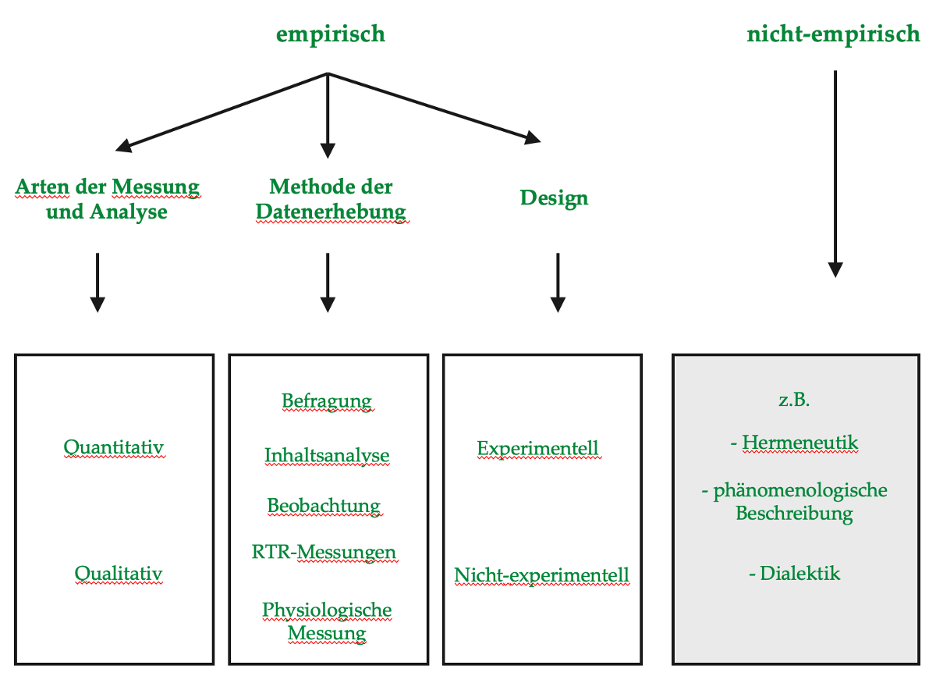
Wir möchten für die Verständlichkeit zunächst Experimente begrifflich einordnen. Forschung kann empirisch und nicht-empirisch erfolgen. Empirisch kann sich hierbei auf die Arten der Messung und Analyse, die Methode der Datenerhebung oder das Design beziehen. Experimente stellen keine Methode der Datenerhebung dar. Beim Experiment können verschiedene Methoden der Datenerhebung zum Einsatz kommen wie bspw. die Befragung oder Inhaltsanalyse. Lediglich das Design kann entweder experimentell oder nicht-experimentell sein.
Das Ziel von Experimenten ist es, herauszufinden, inwiefern eine bestimmte Maßnahme (Unabhängige Variable/Treatment) auf ein Ergebnis wirkt (Abhängige Variable). Sie sind bspw. neben Langzeitstudien eine der wenigen Forschungsmethoden, um Kausalschlüsse zu ziehen, d. h. die Auswirkungen auf die AV auf die Wirkung von UV(s) zurückzuführen.
Anwendungsmöglichkeiten
In der Medizin kann experimentelle Forschung sehr relevant sein, wenn es zum Beispiel um die Testung von neuen Medikamenten geht. Hierbei wird getestet, inwiefern die Einnahme des neuen Medikamentes Folgen bedingt, die im schlimmsten Fall tödlich sein können. Auch in der Psychologie spielen Experimente eine zentrale Rolle.
In der Kommunikationswissenschaft sind Experimente ebenfalls ein wichtiger Teil des Erkenntnisgewinns, da sie nicht nur Schlüsse zur Korrelation zulassen, sondern zur Kausalität. Ein Experiment kann beispielsweise die Wirkung von Gewaltdarstellung in Social Media auf die Aggressivität untersuchen. Ein anderes Beispiel wäre, inwiefern die Medienberichterstattung sich auf die Einschätzung der Relevanz von Themen auswirkt.
Experimente können also als wichtiges Mittel dienen, um Wissen über Wirkungszusammenhänge zu generieren.
Experimente: Korrelation vs. Kausalität
Korrelationen beschreiben lediglich die Zusammenhangsstärke von zwei Variablen. Beispielsweise kann eine Korrelation lediglich Aussagen darüber treffen, dass mit der Zunahme an Lernzeit, Schulnoten besser sind. Doch es können keine Aussagen über alle anderen möglichen Einflussfaktoren auf die Schulnoten gemacht werden. Die Verbesserung in den Schulnoten kann durch Faktoren wie eine bessere finanzielle Lage oder andere Lehrer bedingt sein. Um Aussagen über die Wirksamkeit verschiedener potenzieller Einflussfaktoren auf die Schulnoten machen zu können, braucht es unter anderem Experimente.
Vorteile und Nachteile von Experimenten
Vorteile:
- Ursache-Wirkung-Beziehungen: Feststellung einer Einflussvariable (Treatment) und einer Variable, auf die Treatment wirkt
- Hohe Kontrolle: Ergebnisse akkurater durch Kontrolle der Einflussfaktoren
- Reproduzierbarkeit: Experimente sind oft wiederholbar
- Messbarkeit: Hohe Messbarkeit der Variablen
Nachteile:
- Künstliche Umgebung: Ergebnisse womöglich nicht auf Realität übertragbar aufgrund der Künstlichkeit in Laborsetting
- Generalisierbarkeit: Schwierigere Verallgemeinerbarkeit durch künstliche Umgebung
- Kosten und Aufwand: Zeit, komplexe Designs, Teilnehmerzahl als Faktoren
Experimente
Kausalitätsproblem
In den 2000er Jahren konnte in den USA ein starker Zusammenhang zwischen der Anzahl an Toten durch Blitzeinschläge und dem Pro-Kopf Konsum von Fleisch beobachtet werden. Dieser Zusammenhang scheint aus der Luft gegriffen – ist er vielleicht auch. Denn nur, weil hier eine Korrelation festzustellen ist, ist noch keine Kausalität gegeben.
Das Kausalitätsproblem beschreibt kurzgefasst, dass zwar zahlreiche Korrelationen festgestellt und empirisch beobachtet werden können, diese aber nicht zwangsläufig auch auf Kausalität gründen.
Das weitere Beispiel soll diesen Fehlschluss erklären: eine Befragung ergibt, dass Vielseher mehr Angst als Wenigseher haben, Opfer eines Verbrechens zu werden. Nun könnte angenommen werden, dass die Menge des Fernsehens der Grund für die Angst ist, Opfer eines Verbrechens zu werden. Doch viele andere Gründe können diesen Zusammenhang erklären. So beispielsweise, dass Fernsehen (UV) Angst kultiviert (AV), ängstliche Menschen (UV) lieber zu Hause bleiben und fernsehen (AV) oder es sich nur um eine Scheinkorrelation handelt, z. B., wenn die Befragung in einer kriminellen Umgebung durchgeführt wurde.
Es ist also nicht möglich, nur anhand eines Messzeitpunktes eine Kausalaussage zu machen. Eine Lösung bieten Längsschnittstudien oder Experimente.
Kausalität kann nur unter folgenden Bedingungen angenommen werden:
- Korrelation zweier Zustände
- Zeitliche Reihenfolge zwischen Zustände: Ursache muss Wirkung vorausgehen
- Ausschluss von Einfluss durch Störfaktoren: Zustände bilden isoliertes System
- Ausschluss systemischer Messfehler bei Messung der Zustände
Vorgehensweise
Wir wollen uns nun mit der Vorgehensweise von Experimenten beschäftigen. Grundsätzlich geht es um die Manipulation von unabhängigen Variablen bzw. einer unabhängigen Variablen (auch genannt: Treatment) und die Messung der Auswirkung auf die abhängige Variable.
Denn, um eine Aussage über die Wirkung des Treatments machen zu können, benötigt es einer Kontrollgruppe oder eine Vorhermessung.
Zentrale Eigenschaften von Experimenten:
• Manipulation: mindestens eine unabhängige Variable wird vom Forscher aktiv und systematisch manipuliert und ihr Effekt auf die abhängige Variable gemessen, z. B. die Art von Darstellung der Gewalt in Medien
• Kontrolle: Störvariablen wie ein Geschlecht oder persönliche Erfahrung mit Gewalt werden kontrolliert und ihr Einfluss minimiert/eliminiert, z. B. durch Randomisierung oder Konstanthalten des Einflusses
Störvariablen können problematisch sein, wenn sie nicht kontrolliert werden. Denn sie lassen Raum für Konfundierung. Konfundierung heißt, dass Störvariablen systematisch mit dem Treatment variieren, sodass der Effekt auf die AV nicht mehr auf das Treatment zurückgeführt werden kann. Wenn bspw. drei Gruppen jeweils positive, negative und neutrale Beiträge über Friedrich Merz sehen, so kann in diesem Fall die Parteizugehörigkeit der Rezipienten/Versuchspersonen als Störvariable problematisch werden. Um diese Störvariable zu kontrollieren, kann zum Beispiel sichergestellt werden, dass der Anteil an Unionswählern in allen drei Gruppen etwa gleich ist, sodass dieser Einfluss nicht variiert.
Between Group Design vs Within Group Design und Hypothesenbildung
Experimente können auf Basis eines Between Group (Between Subject) Designs oder eines Within Group (Within Subject) Designs durchgeführt werden. Der hauptsächliche Unterschied liegt darin, dass Between Group Designs Auswirkungen verschiedener Treatments durch den Vergleich der Reaktionen unterschiedlicher Gruppen zum gleichen Messzeitpunkt vergleicht, wobei jede Person nur einem Treatment zugewiesen wird. Within Group Designs vergleichen die Auswirkungen verschiedener Treatments durch den Vergleich der Reaktionen der selben Personen auf mehrere Treatments, wobei jede Person allen Treatments zu unterschiedlichen Zeitpunkten ausgesetzt wird. Graphisch werden unten die wesentlichen Unterschiede der beiden Designs verdeutlicht:
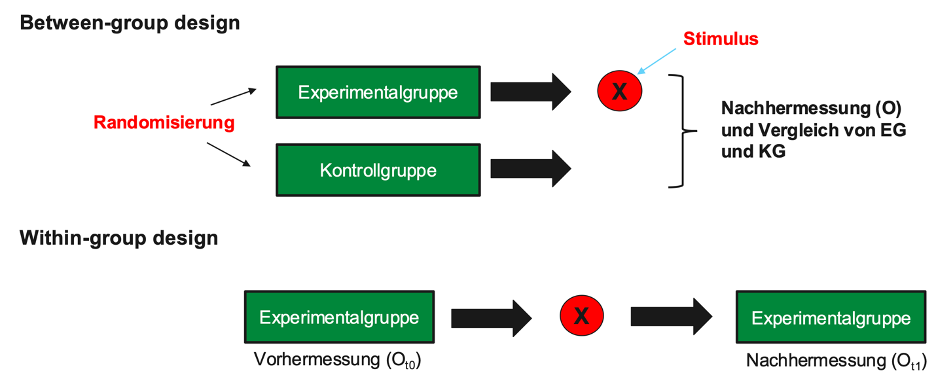
Die folgende Übersicht fasst die Vor- und Nachteile der beiden Designs zusammen:

Between Group Design – Hypothesenbildung:
„Personen, die A erleben, verhalten sich anders als Personen, die B erleben.“
Bsp.: „Personen, die mit einem empathisch formulierten KI-Chatbot interagieren, bewerten diesen als vertrauenswürdiger als andere Personen, die mit einem sachlich formulierten Chatbot interagieren.“
Between Group Design – Statistische Auswertung:
Withtin Group Design – Hypothesenbildung:
„Personen verhalten sich unter Treatment A anders als unter Treatment B.“
Bsp.: „Dieselbe Person bewertet einen KI-Chatbot als vertrauenswürdiger, wenn er empathisch formuliert ist, als wenn er sachlich formuliert ist.“
Within Group Design – Statistische Auswertung:
- Abhängiger t-Test (zwei Bedingungen)
- Repeated Measures ANOVA (mehr als zwei Bedingungen)
Ein- vs Mehrfaktorielle Designs
Experimente können außerdem auch unterschieden werden nach der Anzahl an unabhängigen Variablen, die manipuliert werden. So wird von Einfaktoriellen Designs gesprochen, wenn nur eine unabhängige Variable auf mehreren Stufen manipuliert wird. Eine Variable kann beispielsweise die Art von Gewaltdarstellung sein, dessen Stufen die folgenden sein können: TV-Gewalt, Print-Gewalt, Social Media-Gewalt. Ziel ist der Vergleich der Effekte zwischen den Stufen.
Beim mehrfaktoriellen Design werden mehrere Variablen auf mehreren Stufen manipuliert. Zum Beispiel kann die erste Variable wie im vorherigen Beispiel die Art von Gewaltdarstellung mit ihren Stufen sein und die zweite Variable die Dauer der Gewaltdarstellung sein, dessen Stufen die folgenden sind: kurz, lang. Es soll schließlich die Aggressivität gemessen werden. Die Multiplikation der Anzahl der Stufen pro Variable mit der Anzahl der Stufen der anderen Variablen bildet die Anzahl der Gruppen. Hier also 3 x 2 = 6 Gruppen.
Datenanalyse: Experimente in R
In der kommunikationswissenschaftlichen Forschung werden häufig experimentelle Designs eingesetzt. In diesem Artikel zeigen wir anhand des Datensatzes incvlcomments, wie du experimentelle Daten mit R, dem tidyverse und dem speziell für die Kommunikationswissenschaft entwickelten Package tidycomm analysieren kannst – von der Datensichtung bis zur Hypothesentestung.
Datensichtung
Zunächst wird der Datensatz geladen und ein erster Überblick gewonnen.
#install packages
install.packages("tidyverse")
install.packages("tidycomm")
#activate packages
library(tidyverse)
library(tidycomm)
#define data by assigning the tidycomm dataset incvlcomments to data
data <- incvlcomments
glimpse(data) # schneller Überblick in der Konsole
View(data) # tabellarische Darstellung
Der Datensatz umfasst 3856 Beobachtungen und 22 Variablen aus einer Onlinebefragung von 964 Personen.

Datenbereinigung
Ein sorgfältiger Umgang mit Daten ist essenziell:
• Missings kennzeichnen: z. B. -9 als fehlende Werte erkennen.
• Plausibilität prüfen: z. B. Entfernen von Abbrechern oder Speedys.
• Vorsichtige Bereinigung: immer hypothesengeleitet und transparent.
Der Datensatz incvlcomments ist bereits gut bereinigt und kann direkt analysiert werden.
Datenmodifikation
Zur Vorbereitung der Hypothesentestung werden Variablen umkodiert oder zusammengefasst:
• Gruppenbildung: ähnliche Ausprägungen zusammenführen.
• Indizes bilden: z. B. Mittelwerte mehrerer Items.
• Umkodierungen: z. B. Drehen von Skalen.
Übungen
Vor jeder R Session sollten die packages aktiviert werden. Vor der ersten Benutzung müssen die packages installiert werden.
#descriptive statistics: issue
data %>%
tab_frequencies(issue) %>%
visualize()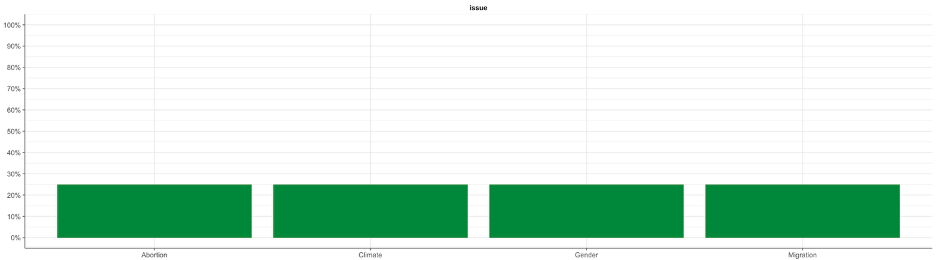
#mutate boolean variable male, so that it is numeric for t-test() and describe()
data_numeric <- data %>%
mutate(male_num = as.numeric(male))
data_numeric <- data %>%
tab_frequencies(male_num) %>%
visualize()
data %>%
describe(harm_to_society) %>%
visualize()
data %>%
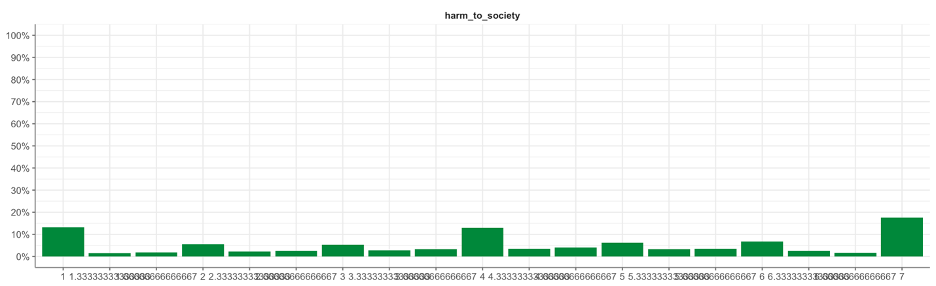
tab_frequencies(harm_to_society) %>%
visualize()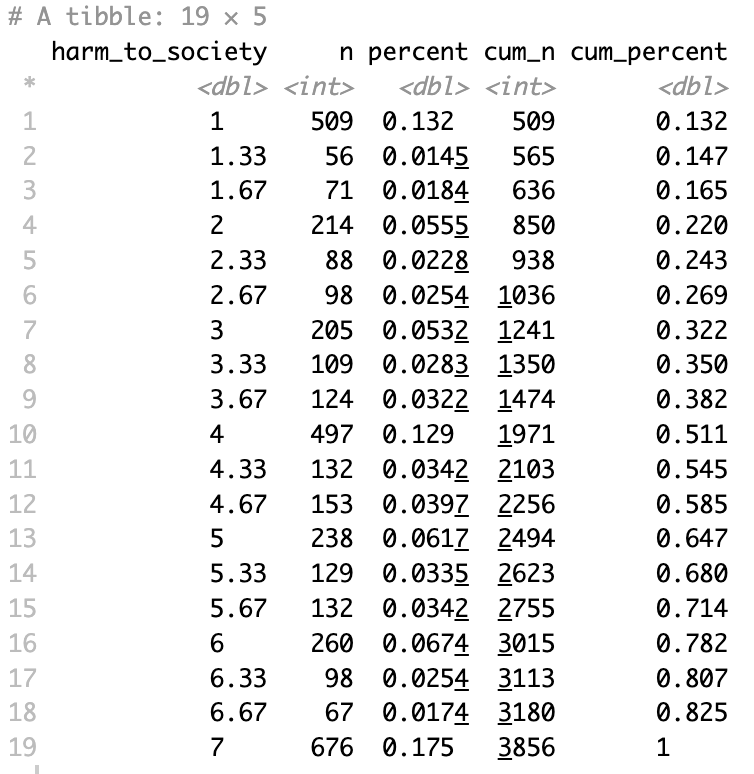
a) Führe einen t-Test zwischen den Variablen male und harm_to_society durch und interpretiere p-Wert, t-Wert und Cohen’s d.
#t-Test male -> harm_to_society
data %>%
t_test(male, harm_to_society)
- p-Wert: .101 deutet auf nicht signifikantes Ergebnis
- t-Wert: -1,642 weist auf moderate Abweichung von Mittelwert unter Nullhypothese hin
- Cohen‘s d: -0.053 sehr kleiner Effekt; geringerer Mittelwert der ersten Gruppe im Vergleich zur zweiten Gruppe hat kaum Auswirkungen
b) Überprüfe folgende Behauptung: „Die Leute finden Beiträge auf Social Media bestimmt vor allem dann gefährlich für die Gesellschaft, wenn es um Themen wie Gender geht und nicht, wenn es um Themen wie Klima geht.“
- Schritt 1 Variablen: UV: issue, AV: harm_to_society
- Schritt 2 Skala: UV: kategorial, AV: metrisch
- Schritt 3 Testauswahl: ANOVA mit Post-hoc-Test für Gruppenvergleich zwischen Gender und Climate
- Schritt 4 Test:
#ANOVA issue -> harm_ to_society
data %>%
unianova(issue, harm_to_society, post_hoc = TRUE) %>%
visualize()
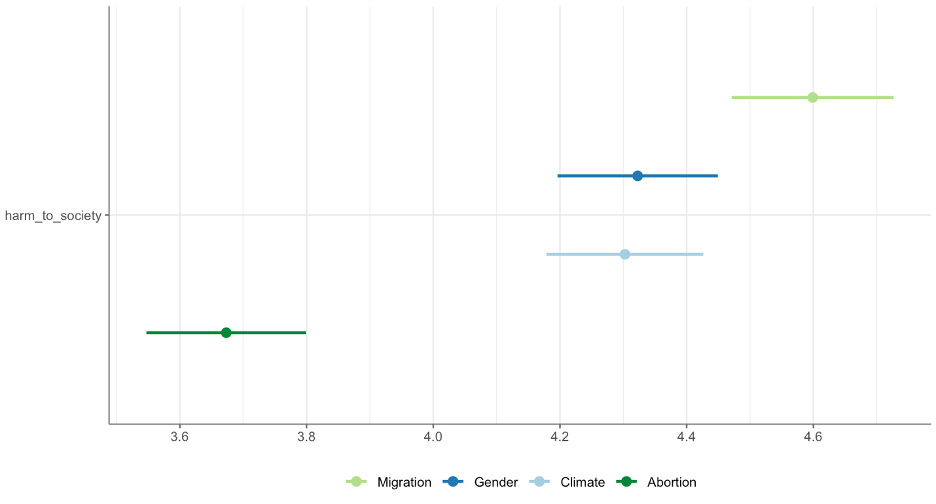
- Schritt 5 Hypothesentest: Post-hoc-Test nötig für Gruppenvergleich zwischen Migration und Climate
#post-hoc model
model <- data %>%
unianova(issue, harm_to_society, post_hoc = TRUE)
View(model)

- Blick auf contrast: Gender-Climate erlaubt Aussage, dass es zwischen diesen beiden Gruppen keinen signifikanten Unterschied gibt (p = 0.99), wobei bei Gender der Effekt (d = -0.01) (Zusammenhangsstärke mit harm_to_society), kaum niedriger ist als bei Climate.
- Das Thema Gender scheint sich in Bezug auf den Zusammenhang mit Gefahr für die Gesellschaft kaum vom Thema Klima unterscheiden.
Referenz
Koch, T., Peter, C., & Müller, P. (2018). Das Experiment in der Kommunikations- und Medienwissenschaft. In Studienbücher zur Kommunikations- und Medienwissenschaft. https://doi.org/10.1007/978-3-658-19754-4