
tidycomm aktivieren
Stellen Sie zunächst sicher, dass das tidycomm-Package mittels install.packages() installiert (nur ein einziges Mal installieren, aber denken Sie an die Anführungszeichen!) und mittels library() geladen ist.
Befehl:
# install.packages("tidycomm")
library(tidycomm)Überblick über tidycomm-Funktionen
- tab_frequencies(): Häufigkeitstabelle für nominal- und ordinalskalierte Variablen
- describe_cat(): Lagemaße für nominal- und ordinalskalierte Variablen
- describe(): Lage- und Streuungsmaße für metrische Variablen
- tab_percentiles(): Perzentile für metrische Variablen
- visualize(): veranschaulicht Ergebnisse (z.B. als Boxplot, Histogramm, Balkendiagramm)
- _scale(): verschiedene Funktionen zum Transformieren von Skalen
describe_cat() und describe()
describe_cat()
Die Funktion describe_cat()(„describe categorial variables“) gibt Kennzahlen für nominal– und ordinalskalierte Variablen aus (z.B. Modus, Anzahl der Kategorien, fehlende Werte).
Befehlstruktur:
data %>%
describe_cat(variable1, variable2, variable3) %>%
visualize() # optional für Balkendiagramm (absolute Häufigkeiten)Veranschaulichung: describe_cat()kann mit dem visualize()-Befehl kombiniert werden, um eine kategoriale Variable grafisch darzustellen. Dies ergibt ein Balkendiagramm, das absolute Häufigkeiten darstellt.
Beispiel:
Wir wollen zunächst die geografische Verteilung unserer Befragten betrachten. Dazu lassen wir uns den Modus der nominalskalierten Variable country aus dem WoJ-Datensatz ausgeben.
Befehl:
WoJ <- WoJ # speichert WoJ in der Environment
WoJ %>%
describe_cat(country)## # A tibble: 1 × 6
## Variable N Missing Unique Mode Mode_N
## * <chr> <int> <int> <dbl> <chr> <int>
## 1 country 1200 0 5 Denmark 376 Die Analyse der geografischen Verteilung im WoJ-Datensatz ergibt, dass Dänemark mit 376 Nennungen von insgesamt 1200 Beobachtungen am häufigsten vertreten ist, was es zum Modus der Stichprobe macht.
describe()
Die Funktion describe()berechnet Lage- und Streuungsmaße für mindestens eine metrische Variable (z.B. Mittelwert, Quantile, Standardabweichung, Spannweite, Minimum und Maximum).
Befehlsstruktur:
data %>%
describe(variable1, variable2, variable3) %>%
visualize() # optional für BoxplotVeranschaulichung: Die Funktion describe()kann mit dem visualize()-Befehl kombiniert werden. Die Kombination ergibt einen Boxplot für die metrische Variable.
Beispiel:
Wir wollen die Lagemaße für die metrische Variable autonomy_selection aus dem WoJ-Datensatz berechnen.
Befehl:
WoJ %>%
describe(autonomy_selection)## # A tibble: 1 × 15
## Variable N Missing M SD Min Q25 Mdn Q75 Max Range
## * <chr> <int> <int> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 autonom... 1197 3 3.88 0.803 1 4 4 4 5 4
## # ℹ 3 more variables: CI_95_LL <dbl>, CI_95_UL <dbl>, Skewness <dbl>,
## # Kurtosis <dbl> Der Mittelwert der Autonomie beträgt M = 3,88 (SD = 0,80). Die Verteilung der Werte reicht von einem Minimum von 1 bis zu einem Maximum von 5, mit einer Spannweite von 4. Der Median liegt bei 4, ebenso wie das 25. und 75. Perzentil, was darauf hinweist, dass die meisten Werte um den Median zentriert sind.
Tipp: Mit dem Abruf der Hilfe-Funktion ?tidycomm::describe() und ?tidycomm::describe_cat() werden die Spalten der Ausgabetabelle genau erklärt.
tab_frequencies() und tab_percentiles()
tab_frequencies()
Die Funktion tab_frequencies() gibt eine Häufigkeitstabelle für mindestens eine Variable aus. Dies ist für nominal- und ordinalskalierte Variablen relevant, da metrische Variablen nur mittels gruppierter Häufigkeitstabellen dargestellt werden können.
Befehlsstruktur:
data %>%
tab_frequencies(variable1, variable2, variable3)
visualize() # optional für Histogramm, oder Balkendiagramm mit relativen HäufigkeitenVeranschaulichung: Die Funktion tab_frequencies()kann ebenfalls mit dem visualize()-Befehl zur Veranschaulichung der Häufigkeiten kombiniert werden. Für eine nominal- und ordinalskalierte Variable wird automatisch ein Balkendiagramm erstellt, das relative Häufigkeiten abbildet. Bei einer metrischen Variable im Argument der Funktion tab_frequencies()wird ein Histogramm erstellt.
Beispiel:
Wir wollen uns eine Häufigkeitstabelle für die Variable country ausgeben lassen. Wir wissen bereits, dass der Modus der Variable „Demark“ ist. Aber wie viel Prozent der Journalist:innen sind denn genau in Dänemark angestellt?
WoJ %>%
tab_frequencies(country)## # A tibble: 5 × 5
## country n percent cum_n cum_percent
## * <fct> <int> <dbl> <int> <dbl>
## 1 Austria 207 0.172 207 0.172
## 2 Denmark 376 0.313 583 0.486
## 3 Germany 173 0.144 756 0.63
## 4 Switzerland 233 0.194 989 0.824
## 5 UK 211 0.176 1200 1 Etwa 31% der Journalist:innen aus dem Datensatz arbeiten in Dänemark.
tab_percentiles()
Die Funktion tab_percentiles()stellt die Perzentile mindestens einer metrischen Variable tabellarisch dar. Perzentile geben an, wie die Werte einer Variable innerhalb der Stichprobe verteilt sind.
Befehlsstruktur:
data %>%
tab_percentiles(variable1, variable2, variable3)Beispiel:
Wir wollen uns die Perzentile der metrischen Variable work_experience ausgeben lassen, um ein detailliertes Bild über die Verteilung der Berufserfahrung der Befragten zu erhalten.
WoJ %>%
tab_percentiles(work_experience)## # A tibble: 1 × 11
## Variable p10 p20 p30 p40 p50 p60 p70 p80 p90 p100
## * <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 work_experience 4 7 10 14 17 20 25 28 33 53Wir können nun ausgewählte Perzentile interpretieren:
- Das 10. Perzentil beträgt 4 Jahre, was darauf hindeutet, dass 10% der Befragten 4 Jahre oder weniger Berufserfahrung haben.
- Der Median (50. Perzentil) der Berufserfahrung beträgt 17 Jahre, was bedeutet, dass die Hälfte der Befragten 17 Jahre oder weniger Erfahrung im Berufsleben aufweisen.
- Das 90. Perzentil liegt bei 33 Jahren, was anzeigt, dass 90% der Befragten 33 Jahre oder weniger an Berufserfahrung haben.
- Das 100. Perzentil, welches das Maximum darstellt, beträgt 53 Jahre Berufserfahrung.
visualize()
Hier zusätzlich noch ein kleiner Überblick über den oben bereits erwähnten visualize()-Befehl aus tidycomm, der alle Lagemaße mittels passender Grafiken visualisieren kann. Dazu muss nur %>% visualize()an die Funktion angehängt werden, die das Lage- oder Streuungsmaß berechnet.
Für nominal- oder ordinalskalierte Variablen:
- describe_cat()+ visualize(): Balkendiagramm, das absolute Häufigkeiten abbildet
- tab_frequencies()+ visualize(): Balkendiagramm, das relative Häufigkeiten abbildet
Für metrische Variablen:
- describe()+ visualize(): Boxplot
- tab_frequencies()+ visualize(): Histogramm
_scale()-Funktionen
Diese Funktionen richten sich an etwas fortgeschrittenere R-Nutzer:innen, die ihr Datenmanagement über besonders bequeme Funktionen („Convenience-Functions“) noch schneller und effizienter gestalten möchten. Mit den verschiedenen _scale()-Funktionen im tidycomm-Package können Sie nämlich Skalen sehr einfach verändern.
- reverse_scale(): dreht eine Skala auf den Kopf, d.h. Minimum und Maximum tauschen Plätze.
- minmax_scale(): verkleinert oder vergrößert eine Skala mit einem neuen Minimum/Maximum unter Beibehaltung der Abstände.
- center_scale(): subtrahiert den Mittelwert von jedem einzelnen Datenpunkt, um eine Skala bei einem Mittelwert von 0 zu zentrieren.
- z_scale(): funktioniert wie center_scale(), aber teilt das Ergebnis auch durch die Standardabweichung, um es mit anderen z-standardisierten Verteilungen vergleichbar zu machen.
- setna_scale(): definiert fehlende Werte.
- recode_cat_scale(): kodiert nominal- oder ordinalskalierte Variablen in neue nominal- oder ordinalskalierte Variablen um.
- categorize_scale():wandelt eine intervall- bzw. verhältnisskalierte Skala in eine nominal- oder ordinalskalierte Skala um, indem es sie in Intervalle / Gruppen einteilt.
reverse_scale()
Die Funktion reverse_scale()dreht eine Skala auf den Kopf, d.h. Maximum und Minimum tauschen Plätze. Es wird automatisch eine neue Spalte mit der gedrehten Variable erstellt, die mit _rev als Namenszusatz gekennzeichnet ist.
Beispiel:
Die Skala von ethics_1 reicht von 1 bis 5, dabei bedeutet 5, dass sich die befragten Journalist:innen stark an Ethik-Kodizes orientieren. Bei den drei anderen ethics-Variablen ist es genau umgekehrt (1 = Orientierung an Ethik-Kodizes). Bei einer Indexberechnung aus den vier ethics-Variablen muss ethics_1 deshalb gedreht werden, sodass die Skala von 5 bis 1 reicht. Die alte und die neue gedrehte Variable können wir uns mit dem dyplr select-Befehl anzeigen lassen.
Befehl:
WoJ %>%
reverse_scale(ethics_1,
lower_end = 1,
upper_end = 5) %>%
dplyr::select(ethics_1, ethics_1_rev)## # A tibble: 1,200 × 2
## ethics_1 ethics_1_rev
## <dbl> <dbl>
## 1 2 4
## 2 1 5
## 3 2 4
## 4 1 5
## 5 2 4
## 6 2 4
## 7 1 5
## 8 2 4
## 9 1 5
## 10 1 5
## # ℹ 1,190 more rowsminmax_scale()
Die minmax()-Funktion gibt einer metrischen Skala einen neuen Wertebereich. Sie vergrößert oder verkleinert die Skala, indem für Maximum und Minimum in der Funktion neue Werte festgelegt werden. Die Abstände zwischen den Skalenpunkten bleiben dabei gleich. Hier wird wie bei allen _scale()-Funktionen ebenso eine neue Spalte im Datensatz erstellt.
Beispiel:
Die Variable autonomy_emphasis (Skala 1 bis 5) soll mit einer anderen Variable verglichen werden, deren Skala von 1 bis 10 reicht. Deshalb soll autonomy_emphasis ebenfalls mit einer Skala von 1 bis 10 dargestellt werden.
Befehl:
WoJ %>%
minmax_scale(autonomy_emphasis,
change_to_min = 1,
change_to_max = 10) %>%
dplyr::select(autonomy_emphasis, autonomy_emphasis_1to10)## # A tibble: 1,200 × 2
## autonomy_emphasis autonomy_emphasis_1to10
## <dbl> <dbl>
## 1 4 7.75
## 2 4 7.75
## 3 4 7.75
## 4 5 10
## 5 4 7.75
## 6 4 7.75
## 7 4 7.75
## 8 3 5.5
## 9 5 10
## 10 4 7.75
## # ℹ 1,190 more rowscenter_scale()
Die Funktion center_scale()subtrahiert den Mittelwert von jedem einzelnen Datenpunkt, um eine metrische Skala bei einem Mittelwert von 0 zu zentrieren. Die Werte links vom Mittelwert erhalten ein negatives Vorzeichen.
Beispiel:
WoJ %>%
center_scale(autonomy_selection) %>%
dplyr::select(autonomy_selection, autonomy_selection_centered)## # A tibble: 1,200 × 2
## autonomy_selection autonomy_selection_centered
## <dbl> <dbl>
## 1 5 1.12
## 2 3 -0.876
## 3 4 0.124
## 4 4 0.124
## 5 4 0.124
## 6 4 0.124
## 7 4 0.124
## 8 3 -0.876
## 9 5 1.12
## 10 2 -1.88
## # ℹ 1,190 more rowsz_scale()
Die Funktion z_scale()funktioniert wie center_scale(), aber die Skala ist zusätzlich z-standardisiert. Eine Skala wird z-standardisiert, um die Werte auf eine Standardnormalverteilung mit einem Mittelwert von 0 und einer Standardabweichung von 1 zu bringen. Dies ermöglicht Vergleichbarkeit zwischen verschiedenen Skalen oder Variablen.
Beispiel:
Mithilfe von tab_frequencies()und visualize()können wir die nicht-standardisierte und die z-standardisierte autonomy_selection-Variable grafisch gegenüberstellen.
Befehl:
WoJ %>%
z_scale(autonomy_selection) %>%
tab_frequencies(autonomy_selection, autonomy_selection_z) %>%
visualize()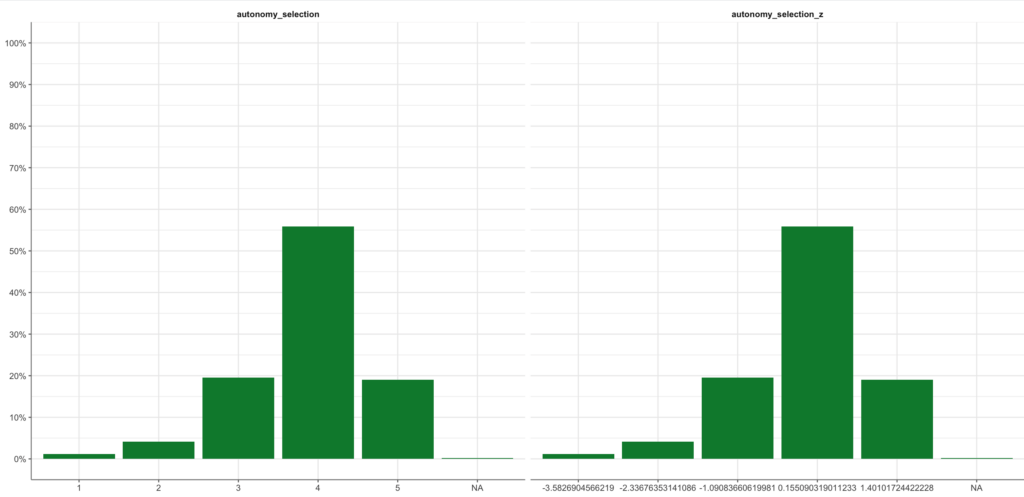
setna_scale()
Mithilfe von setna_scale() können bestimmte Werte als fehlend definiert werden.
Beispiel:
Bei der Variable autonomy_emphasis fällt zum Beispiel auf, dass der Wert 5 zu Fehlern in den Daten geführt hat. Deshalb wollen wir diesen Wert als Missing definieren.
Befehl:
WoJ %>%
setna_scale(autonomy_emphasis, value = 5) %>%
dplyr::select(autonomy_emphasis, autonomy_emphasis_na)## # A tibble: 1,200 × 2
## autonomy_emphasis autonomy_emphasis_na
## <dbl> <dbl>
## 1 4 4
## 2 4 4
## 3 4 4
## 4 5 NA
## 5 4 4
## 6 4 4
## 7 4 4
## 8 3 3
## 9 5 NA
## 10 4 4
## # ℹ 1,190 more rowsrecode_cat_scale()
Um nominal- oder ordinalskalierte Variablen in neue nominal- oder ordinalskalierte Variablen umzukodieren, kann die Funktion recode_cat_scale() verwendet werden.
Beispiel:
Anstelle der Ländernamen bei der nominalen Variable country wollen wir Länderadjektive verwenden. Da uns nur die DACH-Länder (Deutschland, Österreich, Schweiz) interessieren, wollen wir UK und Denmark mit „other“ zusammenfassen.
Befehl:
WoJ %>%
recode_cat_scale(country, assign = c("Germany" = "german",
"Switzerland" = "swiss",
"Austria" = "austrian"), other = "other") %>%
dplyr::select(country, country_rec)## # A tibble: 1,200 × 2
## country country_rec
## <fct> <fct>
## 1 Germany german
## 2 Germany german
## 3 Switzerland swiss
## 4 Switzerland swiss
## 5 Austria austrian
## 6 Switzerland swiss
## 7 Germany german
## 8 Denmark other
## 9 Switzerland swiss
## 10 Denmark other
## # ℹ 1,190 more rowscategorize_scale()
Die Funktion categorize_scale()wandelt eine intervall- bzw. verhältnisskalierte Skala in eine nominal- oder ordinalskalierte Skala um, indem sie sie in Intervalle / Gruppen einteilt.
Beispiel:
Die Variable autonomy_emphasis (Skala 1 bis 5) soll in drei Kategorien eingeteilt werden, die in Worten angeben, wie frei Journalist:innen bei der Auswahl von Nachrichtenschwerpunkten sind. Angaben auf der Skala sollen von 1-2 als „Low“ gekennzeichnet werden, 3 als „Medium“ und von 4-5 als „High“.
Befehl:
WoJ %>%
categorize_scale(autonomy_emphasis,
lower_end =1, upper_end =5,
breaks = c(2, 3),
labels = c("Low", "Medium", "High")) %>%
dplyr::select(autonomy_emphasis, autonomy_emphasis_cat)## # A tibble: 1,200 × 2
## autonomy_emphasis autonomy_emphasis_cat
## * <dbl> <fct>
## 1 4 High
## 2 4 High
## 3 4 High
## 4 5 High
## 5 4 High
## 6 4 High
## 7 4 High
## 8 3 Medium
## 9 5 High
## 10 4 High
## # ℹ 1,190 more rows