
Erklärung eines Multilevel Models (MLM)
Multilevel Modeling, auch bekannt als hierarchische lineare Modellierung, ist eine statistische Methode, die verwendet wird, um Daten zu analysieren, die eine hierarchische oder verschachtelte (engl.: „nested“) Struktur aufweisen. Dies kommt häufig in der sozialwissenschaftlichen, biologischen und medizinischen Forschung vor. Die Kernidee hinter Multilevel Modeling ist es, die Beziehungen zwischen Variablen unter Berücksichtigung der hierarchischen Struktur der Daten zu analysieren.
Warum und wann brauche ich MLMs?
Oft sind Daten innerhalb von Gruppen (wie Bundesländern, Zeitungsverlagen, Schulen) ähnlicher als zwischen Gruppen, d.h. die Beobachtungen innerhalb derselben Gruppe sind nicht unabhängig voneinander. Multilevel Modeling berücksichtigt diese Abhängigkeiten, was zu genaueren Schätzungen und Inferenzen führt und so vor irreführenden Schlussfolgerungen bewahrt, die auftreten können, wenn traditionelle Analysemethoden verwendet werden, die die hierarchische Struktur der Daten nicht beachten.
Beachte: Wann immer Daten in einer verschachtelten, hierarchischen Struktur vorliegen, lohnt sich die Nutzung eines Multilevel Models (MLM).
Beispiele für hierarchisch strukturierte Daten
Beispiel 1: Der WoJ-Datensatz, der Teil vom R-Package tidycomm ist, ist ein hierarchisch strukturierter Datensatz. Es handelt sich dabei um eine Befragung von 1200 Journalist*innen aus 5 europäischen Ländern. Wir sagen dazu: die Journalist*innen (Ebene 1) sind in den Ländern (Ebene 2) verschachtelt. Das heißt, die aufgezeichneten Antworten auf ethische Fragestellungen oder Autonomieitems sind möglicherweise nicht zwischen den Fällen im Datensatz unabhängig. Stattdessen werden die Antworten von Journalist*innen, die aus demselben Land stammen (und dementsprechend in einem ähnlichen kulturellen, politischen und medialen System sozialisiert wurden), einander vermutlich ähnlicher sein als Antworten von Journalist*innen, die aus unterschiedlichen Ländern stammen.
Beispiel 2: Der incvlcomments-Datensatz, der Teil vom R-Package tidycomm ist, ist ebenfalls ein hierarchisch strukturierter Datensatz. Es handelt sich dabei um ein Experiment, bei dem jede*r der 964 Teilnehmer*innen insgesamt 4 Nutzerkommentare hinsichtlich deren Offensivität bewerten musste (das macht also 964 x 4 = 3856 Fälle). Wir sagen dazu: die Kommentare (Ebene 1) sind in den Teilnehmer*innen (Ebene 2) verschachtelt. Das heißt, die aufgezeichneten Reaktionen der Teilnehmer*innen auf die Nutzerkommentare sind möglicherweise nicht zwischen den Fällen im Datensatz unabhängig. Stattdessen werden die Ratings von Kommentaren, die von demselben Teilnehmer stammen (und dementsprechend auf Basis derselben individuellen Charakteristika bewertet wurden wie Alter, Geschlecht, Bildungsniveau, Ekelempfinden), einander vermutlich ähnlicher sein als Ratings von Kommentaren, die von anderen Teilnehmer*innen abgegeben wurden (die ja auch ganz andere individuelle Charakteristika besitzen).
Exploration in R
Die R-Hilfefunktion bietet Informationen über alle Datensätze, die mittels eines Packages distribuiert werden. So können Sie erfahren, dass es sich bei dem WoJ– und incvlcomments-Datensätzen um hierarchisch organisierte Daten handelt:
?tidycomm::WoJDadurch öffnet sich die Hilfeseite mit der Dokumentation des Datensatzes, der wir entnehmen können, dass der Datensatz 1.200 befragte Journalist*innen als Fälle enthält, die in 5 Ländern verschachtelt sind. Diese 5 Länder sind in der Variable „country“ hinterlegt:
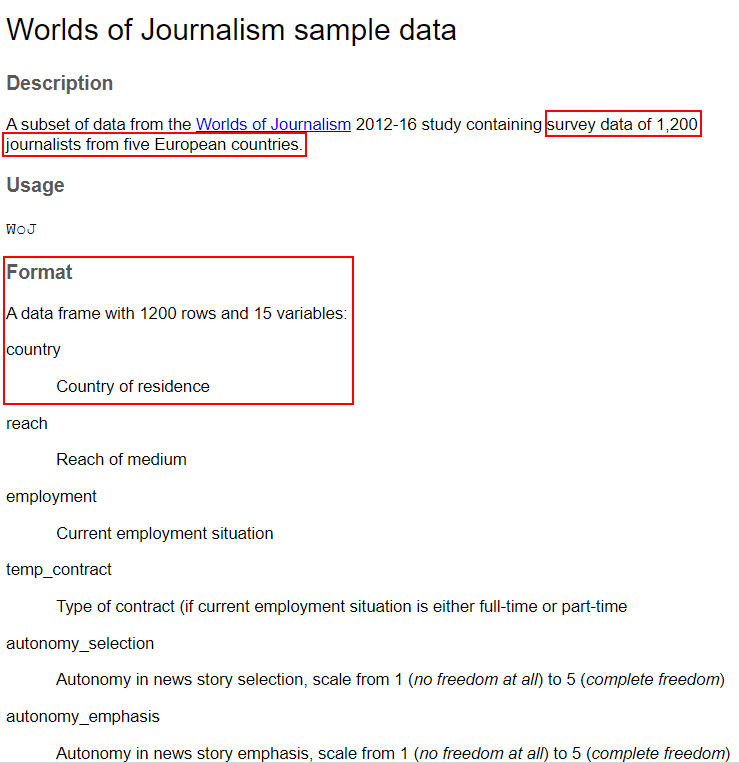
Schritt-für-Schritt-Anleitung zur Durchführung eines MLMs
Schritt 1: Hypothese formulieren
Am Anfang jedes statistischen Analyseverfahren steht zunächst ein Erkenntnissinteresse. Bevor wir also mit der Auswertung mittels MLM beginnen, müssen wir zunächst eine überprüfbare Hypothese aufstellen. Aus theoretischen Vorüberlegungen nehmen wir an, dass im Redaktionsalltag erfahrenen Journalist*innen eher zugetraut wird, unabhängige Entscheidungen zu treffen. Wir vermuten:
H1: Journalist*innen mit umfangreicherer Berufserfahrung (‚work_experience‘) besitzen eine höhere Autonomie in der Auswahl von Nachrichten (“autonomy_selection“) als ihre weniger erfahrenen Kolleg*innen.
Theoretisch könnte diese Hypothese auch mittels einer einfachen linearen Regression untersucht werden, da sie eine direkte Beziehung zwischen zwei Variablen auf einer Ebene (individuelle Ebene der Journalist*innen) beschreibt. Der Datensatz umfasst allerdings Journalist*innen aus verschiedenen Ländern. Diese Länder könnten unterschiedliche Mediensysteme, politische Kontexte und Kulturen aufweisen, was wiederum die Autonomie der Journalist*innen neben individuellen Einflüssen verändern könnte. Ein MLM kann diese kontextuellen Unterschiede berücksichtigen, indem es Länder als eine höhere Ebene in das Modell einbezieht.
MLMs erlauben es zudem, sowohl sogenannte feste Effekte (wie die Berufserfahrung) als auch zufällige Effekte (wie Länderunterschiede) zu modellieren. Diese Flexibilität ist wichtig, wenn man die Möglichkeit in Betracht zieht, dass die Beziehung zwischen Berufserfahrung und Autonomie in der Nachrichtenauswahl in verschiedenen Ländern unterschiedlich sein könnte.
Schritt 2: Verständnis der Datenstruktur bekommen
Zuerst erkennen wir also, dass unsere Daten hierarchisch sind: Mehrere Beobachtungen, nämlich Journalist*innen (Ebene 1) innerhalb der verschiedenen Länder (Ebene 2). Es ist wahrscheinlich, dass die Autonomie in der Nachrichtenauswahl eines Journalist*innen stärker mit der Autonomie anderer Journalist*innen im selben Land korreliert, als mit der von Journalisten aus anderen Ländern. Diese Art der Datenstruktur, bei der Beobachtungen innerhalb einer Gruppe (hier: Land) tendenziell ähnlicher sind als zwischen den Gruppen, bildet eine typische Voraussetzung für Multilevel Modeling.
Schritt 3: Berechnung des Nullmodels
Das Nullmodell, auch bekannt als Intercept-Only-Modell oder Empty-Modell, dient als Ausgangspunkt für die Analyse hierarchischer Daten. Es ist das einfachste MLM, das man aufstellen kann, und enthält keine erklärenden, unabhängigen Variablen (Prädiktoren) abgesehen vom Intercept (y-Achsenabschnitt). Das Nullmodell berücksichtigt demnach nur die Gruppenstruktur der Daten, indem es für jede Gruppe (z.B. Land, Zeitungsverlag, Schule) einen eigenen Intercept zulässt, der dem jeweiligen Gruppenmittelwert entspricht. In unserem Beispiel entspricht das der durchschnittlichen Autonomie in der Nachrichtenauswahl, die die Journalist*innen im jeweiligen Land angegeben haben (siehe Abbildung).
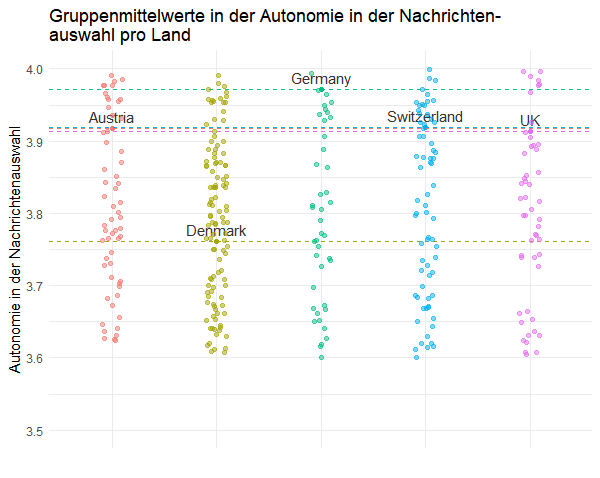
Was sagt uns das Nullmodell inhaltlich?
Wenn Sie keine weiteren Informationen über einen einzelnen Journalisten haben (z.B. individuelle Bildung, Berufserfahrung, usw.), bietet das Nullmodell eine Schätzung basierend auf dem Mittelwert seiner Gruppe (Land). Dieser Mittelwert kann als beste Schätzung dienen, wenn keine weiteren Informationen vorliegen. Im Durchschnitt werden sie die individuelle Autonomie nämlich relativ gut treffen, wenn Sie einfach den Landesmittelwert als Schätzung angeben!
Wozu dient das Nullmodell?
Das Nullmodell im Multilevel Modeling dient demnach als wichtiger erster Schritt, um die Notwendigkeit für komplexere Modelle zu bewerten. Es hat vornehmlich zwei Zwecke:
- ICC-Berechnung (Erklären!): Es kann dazu genutzt werden, den ICC zu berechnen (siehe Schritt 4).
- Benchmark: Das Nullmodell dient als Referenzpunkt, um die Passung komplexerer Modelle mit zusätzlichen erklärenden Variablen (Prädiktoren) zu beurteilen. Durch den Vergleich der Modellanpassung (z.B. mit einem Likelihood-Ratio-Test) kann man beurteilen, ob die Hinzufügung von Prädiktoren eine statistisch signifikante Verbesserung des Modells und damit der Schätzung darstellt.
Wie interpretiere ich das Nullmodell?
Das Nullmodell beinhaltet lediglich den Gesamt-Mittelwert (den Intercept) und die zufälligen Effekte für die Gruppen. Die Interpretation des Nullmodells fokussiert sich daher auf zwei Aspekte:
- Intercept (y-Achsenabschnitt): Dieser Wert gibt den geschätzten durchschnittlichen Wert der abhängigen Variable an, wenn man alle Gruppen betrachtet. Er ist der Startpunkt für die Modellierung der Gruppeneffekte.
- Varianz der zufälligen Effekte: Diese gibt an, wie stark die Gruppen voneinander abweichen. Eine hohe Varianz deutet darauf hin, dass es bedeutende Unterschiede zwischen den Gruppen gibt, was ein Hinweis darauf sein kann, dass ein Multilevel-Modell angebracht ist.
Berechnung in R
Wir erzeugen nun ein Nullmodell in R, indem wir ‚autonomy_selection‘ als abhängige Variable verwenden, und das Land (‚country‘) als zufälliger Effekt. Dazu laden wir zunächst das R Package lme4, mit dem man MLM fitten kann. Dann fitten wir das Modell und lassen uns mit der summary()-Funktion die Ergebnisse anzeigen.
library(lme4) # Lädt das Package zur MLM-Erstellung. Wenn noch nicht installiert, zunächst ausführen: install.packages("lme4")
# NULLMODELL
# Die abhängige Variable ist autonomy_selection
# country wird als zufälliger Effekt für den Intercept berücksichtigt
null_model <- lmer(autonomy_selection ~ 1 + (1 | country), data = WoJ, REML = FALSE)
# Zusammenfassung des Modells anzeigen
summary(null_model)Erklärung der Formelbestandteile:
autonomy_selectionist Ihre abhängige Variable.- Das Tilde-Symbol
~trennt die abhängige Variable (auf der linken Seite) von den unabhängigen Variablen (auf der rechten Seite) in der Modellformel. Es ist eine Art von Zuweisung, die sagt: „Die linke Seite wird durch die rechte Seite erklärt oder vorhergesagt.“ - Die
1steht für den Intercept (auch bekannt als das konstante Glied) des Modells. In einem statistischen Modell ist der Intercept der erwartete Wert der abhängigen Variable, wenn alle unabhängigen Variablen null sind. Im Kontext eines gemischten Modells (wie beilmer) stellt der Intercept den Gruppenmittelwert der abhängigen Variable dar, bevor andere Faktoren oder zufällige Effekte berücksichtigt werden. + (1 | country)fügt das Land als zufälligen Effekt hinzu. Dies bedeutet, dass wir zulassen, dass der Intercept für jedes Land unterschiedlich ist, was die Variation zwischen den Ländern berücksichtigt.REML = FALSEwählt die Maximum-Likelihood-Schätzung anstelle der Restricted Maximum Likelihood, was für Modellvergleiche sinnvoll ist.
Auswertung in R
Dazu betrachten wir zunächst den Output in der Konsole von RStudio:
Linear mixed model fit by maximum likelihood ['lmerMod']
Formula: autonomy_selection ~ 1 + (1 | country)
Data: WoJ
AIC BIC logLik deviance df.resid
2872.2 2887.5 -1433.1 2866.2 1194
Scaled residuals:
Min 1Q Median 3Q Max
-3.6614 0.0896 0.1200 0.2469 1.4972
Random effects:
Groups Name Variance Std.Dev.
country (Intercept) 0.003483 0.05902
Residual 0.639663 0.79979
Number of obs: 1197, groups: country, 5
Fixed effects:
Estimate Std. Error t value
(Intercept) 3.88842 0.03542 109.8Zunächst lohnt die Interpretation der festen Effekte (Fixed Effects):
- Intercept (y-Achsenabschnitt): Der Intercept gibt den geschätzten durchschnittlichen Wert der abhängigen Variable autonomy_selection an, wenn man alle Gruppen (in diesem Fall Länder) gleichzeitig betrachtet. Der Wert von 3.88842 ist der durchschnittliche Grad der Autonomie bei der Nachrichtenauswahl über alle beobachteten Länder hinweg, ohne Berücksichtigung spezifischer Ländermerkmale. Dies deutet darauf hin, dass Journalist*innen im Durchschnitt eine relativ hohe Autonomie bei der Auswahl von Nachrichten haben, unabhängig vom Land, in dem sie arbeiten. Der t-Wert ist sehr hoch, was darauf hindeutet, dass dieser Intercept statistisch signifikant von Null verschieden ist.
Als nächstes lohnt die Interpretation der zufälligen Effekte (Random Effects):
- country Intercept Variance und Standard Deviation: Die Varianz der zufälligen Effekte misst, wie stark die Gruppen (hier: Länder) voneinander abweichen. Die geringe Varianz (0.003483) und Standardabweichung (0.05902) im zufälligen Effekt für Länder zeigt, dass die Unterschiede in der Autonomie der Nachrichtenauswahl zwischen den Ländern relativ gering sind. Dies bedeutet, dass, obwohl Länder als zufällige Effekte in das Modell aufgenommen wurden, die Variabilität der Autonomie über die verschiedenen Länder hinweg nicht sehr ausgeprägt ist.
- Residual Variance und Standard Deviation: Die Residualvarianz gibt die Variabilität in der Autonomie der Nachrichtenauswahl an, die nicht durch die Gruppenzugehörigkeit (hier: Länderzugehörigkeit) erklärt wird. Die relativ hohe Residualvarianz deutet darauf hin, dass es andere Faktoren gibt, die zur Variation in der Autonomie der Nachrichtenauswahl beitragen und die im aktuellen Modell nicht berücksichtigt werden. Dies legt nahe, dass die Einbeziehung weiterer erklärender Variablen neben der Länderzugehörigkeit (wie z.B. unser Fokusprädiktor
work_experience) in ein umfassenderes Modell sinnvoll sein könnte, um ein vollständigeres Bild davon zu erhalten, welche Faktoren die Autonomie bei der Nachrichtenauswahl beeinflussen. Wir haben guten Grund, komplexere Modelle zu fitten!
Zusätzlich kann man sich noch die skalierten Residuen (Scaled Residuals) und die Informationen zur Passung des Modells ansehen:
- Skalierten Residuen (Scaled Residuals): Skalierte Residuen sind die Differenzen zwischen den beobachteten Werten der abhängigen Variablen und den vom Modell vorhergesagten Werten, standardisiert durch eine Schätzung der Standardabweichung der Residuen.
- Normalverteilung: Für viele statistische Modelle ist eine Annahme, dass die Residuen normalverteilt sind. Wenn die skalierten Residuen annähernd normalverteilt sind (d.h., sie bilden eine Glockenkurve, wenn man sie grafisch darstellt), ist dies ein Hinweis darauf, dass das Modell die Daten gut abbildet. Werte der skalierten Residuen, die weit von Null entfernt sind (zum Beispiel größer als 3 oder kleiner als -3), können auf Ausreißer in den Daten hinweisen. Diese extremen Werte können die Modellschätzungen beeinflussen und sollten genauer untersucht werden.
- Homoskedastizität: Ein weiteres wichtiges Kriterium ist, dass die Varianz der Residuen konstant sein sollte (Homoskedastizität). Wenn die Varianz der skalierten Residuen über den Bereich der vorhergesagten Werte gleich bleibt, ist diese Annahme erfüllt. Muster in den Residuen, wie eine Zunahme der Varianz bei größeren vorhergesagten Werten, deuten auf Heteroskedastizität hin, was ein Problem darstellen kann.
- Hier haben die skalierten Residuen von Min -3.6614 bis Max 1.4972. Der Median liegt nahe bei Null und die Quartile (1Q und 3Q) sind ebenfalls relativ nah an Null. Dies deutet darauf hin, dass die Residuen im Großteil der Daten um den Nullwert zentriert sind, was auf eine angemessene Modellpassung hinweist. Der minimale Wert der skalierten Residuen ist -3.6614, was ein potenzieller Ausreißer sein könnte, da er weit von Null entfernt ist. Der maximale Wert von 1.4972 ist weniger besorgniserregend, da er nicht so extrem ist. Die Tatsache, dass die Quartile relativ eng um Null gruppiert sind, darauf hin, dass es keine offensichtlichen Probleme mit der Varianz der Residuen gibt, aber ein letzter Schluss über die Homoskedastizität kann ohne grafische Visualisierung nicht gezogen werden.
- Informationen über die Passung des Modells:
- AIC und BIC sind Maße für die Qualität des Modells unter Berücksichtigung der Anzahl der Parameter – niedrigere Werte deuten auf ein besseres Modell hin. AIC bestraft Modelle für eine hohe Anzahl an Parametern (d.h., für übermäßige Komplexität) und belohnt sie für eine gute Passung an die Daten. BIC benutzt sogar einen noch stärkeren Strafterm für die Anzahl der Modellparameter.
- Log-Likelihood ist ein Maß dafür, wie gut das Modell die beobachteten Daten beschreibt. Es ist ein logarithmiertes Wahrscheinlichkeitsmaß, das die Wahrscheinlichkeit angibt, mit der die beobachteten Daten unter dem gegebenen Modell auftreten könnten. Ein höherer Log-Likelihood-Wert (näher an null oder positiv) deutet auf eine bessere Modellanpassung hin, da dies eine höhere Wahrscheinlichkeit der Daten unter dem Modell bedeutet. Allerdings ist der absolute Wert von Log-Likelihood schwierig zu interpretieren, da er von der Größe der Stichprobe und der Komplexität des Modells abhängt. Daher wird Log-Likelihood oft in vergleichenden Tests zwischen Modellen verwendet, wie z.B. Likelihood-Ratio-Tests.
- Deviance ist ein weiteres Maß für die Modellpassung, das eng mit der Log-Likelihood verbunden ist. Es ist im Grunde genommen die negative zweifache Log-Likelihood. Eine geringere Deviance deutet auf eine bessere Modellpassung hin. Es bedeutet, dass das Modell weniger Abweichungen von den beobachteten Daten aufweist.
Beachte: Durch den Vergleich der Informationen zur Passung des Modells können Sie beurteilen, welches der von Ihnen getesteten Modelle am besten abschneidet und damit auch ob die Hinzufügung weiterer Variablen die Modellpassung signifikant verbessert hat.
Berichten des Ergebnisses
„Im Rahmen unserer Analyse haben wir zunächst ein MLM berechnet, dass sich als Nullmodel bzw. „Empty Model“ auf die Autonomie bei der Nachrichtenauswahl (autonomy_selection) als abhängige Variable konzentrierte und die Länderzugehörigkeit (country) als zufälligen Effekt berücksichtigte, ohne feste Prädiktoren einzubeziehen. Der feste Effekt für den Intercept lag bei 3.88, was auf einen hohen durchschnittlichen Grad der Autonomie bei der Nachrichtenauswahl über alle Länder hinweg hinweist. Die verbleibende hohe Residualvarianz von 0.63 deutet zudem darauf hin, dass es andere Faktoren neben der Länderzugehörigkeit gibt, die zur Variation in der Autonomie der Nachrichtenauswahl beitragen und die im aktuellen Modell nicht berücksichtigt werden und deswegen in den nachfolgenden Modellen betrachtet werden sollen.“
Schritt 4: Berechnung des ICC (Intraclass Correlation Coefficient)
Der Intraclass Correlation Coefficient (ICC) ist ein Maß in der Statistik, das verwendet wird, um die Ähnlichkeit (= Homogenität) von Daten innerhalb derselben Gruppe zu quantifizieren. In Multilevel-Modellen ist der ICC besonders wichtig, da er anzeigt, wie viel der Gesamtvarianz in den Beobachtungen durch die Gruppenstruktur erklärt wird.
Warum berechnet man den ICC?
Ein hoher ICC deutet darauf hin, dass die Gruppenzugehörigkeit einen bedeutenden Einfluss auf die Daten hat. In einem solchen Fall ist die Verwendung eines Multilevel-Modells gerechtfertigt und notwendig, weil traditionelle Analysemethoden ungenauere Schätzungen und Inferenzen liefern würden. Der ICC hilft also zu bestimmen, ob die Datenstruktur ein einfacheres Modell (wie ein lineares Regressionsmodell) oder ein komplexeres Multilevel-Modell erfordert.
Wie interpretiert man den ICC?
Es gibt keinen universell anerkannten „kritischen“ Schwellenwert für den ICC, ab dem ein Multilevel-Modell als notwendig oder geeignet angesehen wird. Die Entscheidung hängt vom Kontext der Studie und dem Forschungsziel ab. Allerdings gibt es einige allgemeine Richtlinien:
- Ein niedriger ICC (z.B. kleiner als 0.05) deutet darauf hin, dass nur ein kleiner Anteil der Gesamtvarianz zwischen den Gruppen liegt. In solchen Fällen könnte ein einfacheres Modell ausreichen.
- Ein hoher ICC (z.B. größer als 0.15) bedeutet, dass ein bedeutender Anteil der Varianz auf die Gruppenzugehörigkeit zurückzuführen ist, was die Verwendung eines Multilevel-Modells nahelegt.
Wie berechne ich den ICC?
ICC=\frac{\sigma_{zwischen}^2}{\sigma_{zwischen}^2+\sigma_{innerhalb}^2}- σ2zwischen ist die Varianz zwischen den Gruppen (z.B. zwischen verschiedenen Ländern).
- σ2innerhalb ist die Residualvarianz innerhalb der Gruppen (z.B. innerhalb der Länder).
Basierend auf den Daten unseres Nullmodells bedeutet das:
- σ2zwischen= 0.003483 (Varianz der zufälligen Effekte für Länder)
- σ2innerhalb = 0.639663 (Residualvarianz)
Der ICC ist somit:
ICC=\frac{0,003483}{0,003483+0,639663}=0,005416Der ICC beträgt somit ca. 0.0054. Dieser Wert gibt den Anteil der Gesamtvarianz an, der auf Unterschiede zwischen den Ländern zurückzuführen ist. Da der Wert sehr niedrig ist, wissen wir, dass nur ein sehr kleiner Anteil der Gesamtvarianz in der Autonomie der Nachrichtenauswahl auf Unterschiede zwischen den Ländern zurückzuführen ist. Mit anderen Worten: die meisten Unterschiede in der Autonomie der Nachrichtenauswahl sind innerhalb der Länder (also zwischen den individuellen Journalist*innen) und nicht zwischen den Ländern.
Berechnung in R
# ICC-BERECHNUNG
# Extrahieren der Varianzkomponenten
var_components <- as.data.frame(VarCorr(null_model))
# Die Varianz für den zufälligen Effekt (Gruppenvarianz)
sigma_squared_group <- var_components$vcov[1]
# Die Residualvarianz
sigma_squared_residual <- attr(VarCorr(null_model), "sc")^2
# Berechnung des ICC
icc <- sigma_squared_group / (sigma_squared_group + sigma_squared_residual)
# Ausgabe des ICC
print(icc)[1] 0.005415604Berichten des Ergebnisses
„Zuvor wurde jedoch der Intraklassen-Korrelationskoeffizient (ICC) berechnet, um den Anteil der Varianz genauer zu bestimmen, der durch Unterschiede zwischen den Ländern erklärt werden kann. Der ICC betrug 0.0054, was darauf hinweist, dass nur 0.54% der Gesamtvarianz in der Autonomie der Nachrichtenauswahl durch die Zugehörigkeit zu einem bestimmten Land bedingt ist. Dieser geringe Wert bestätigt die Vermutung, dass die meisten Unterschiede in der wahrgenommenen Autonomie innerhalb der einzelnen Länder (also zwischen individuellen Journalist*innen) und nicht zwischen den Ländern auftreten. Länderspezifische Faktoren spielen demnach eine untergeordnete Rolle bei der Bestimmung der Autonomie der Nachrichtenauswahl, während individuelle Faktoren möglicherweise eine größere Bedeutung haben.“
Schritt 5: Vollständiges Modell erstellen
Achtung, der vorangegangene Schritt hat gezeigt, dass ein einfaches, lineares Regressionsmodell ebenfalls für die Modellierung der Daten denkbar wäre, da die Gesamtvarianz in der Autonomie der Nachrichtenauswahl gar nicht so sehr bedingt durch die Zugehörigkeit zu einem bestimmten Land bedingt ist (ICC < 0.05). Im Sinne des Erlernens des MLMs setzen wir unsere Modellierung dennoch fort.
Nachdem das Nullmodell erstellt und der ICC berechnet wurde, ist der nächste Schritt die Entwicklung eines vollständigen Multilevel-Modells, das feste Effekte (direkte Einflussfaktoren auf die abhängige Variable) und zufällige Effekte (Varianz zwischen den Gruppen) berücksichtigt. Das Ziel des vollständigen Modells ist es, zu untersuchen, wie verschiedene Prädiktoren die abhängige Variable, in diesem Fall die Autonomie in der Auswahl von Nachrichten (autonomy_selection), beeinflussen, und dabei die hierarchische Struktur der Daten – dass Journalist*innen innerhalb der Länder gruppiert sind – zu berücksichtigen. Unsere spezifische Hypothese („Journalist*innen mit umfangreicher Berufserfahrung (work_experience) besitzen eine höhere Autonomie in der Auswahl von Nachrichten als ihre weniger erfahrenen Kolleg*innen.“) zielt darauf ab zu überprüfen, ob die Berufserfahrung die Autonomität der Nachrichtenselektion von Journalist*innen tatsächlich in die prognostizierte Richtung beeinflusst.
Wie wähle ich Prädiktoren für das Modell aus?
Die Auswahl der Prädiktoren sollte auf theoretischen Überlegungen und der Forschungshypothese basieren. Für unser Beispiel könnten wir folgende Prädiktoren in Betracht ziehen:
- Berufserfahrung des Journalisten (
work_experience): Dies ist der Hauptprädiktor, um unsere Hypothese zu testen. - Art des Arbeitsvertrags (
temp_contract): Kontrolliert den Einfluss von befristeten vs. unbefristeten Verträgen, damit dieser nicht den gemessenen Effekt unseres Hauptprädiktors verzerrt. - Beschäftigungsstatus (
employment): Kontrolliert den Einfluss von Vollzeit- und Teilzeitarbeit, damit dieser nicht den gemessenen Effekt unseres Hauptprädiktors verzerrt.
Es gibt zwei Möglichkeiten, die Prädiktoren zu modellieren. Es muss nun entschieden werden, ob ein Random-Intercept- oder ein Random-Slope-Modell für die Daten und die Forschungsfrage am besten geeignet ist:
- Random-Intercept-Modell: Dieses Modell wird gewählt, wenn die Annahme besteht, dass die Länder sich in ihren Gruppenmittelwerten bezüglich der Autonomie in der Nachrichtenselektion zwar systematisch unterscheiden, aber der Einfluss der Prädiktoren (wie Berufserfahrung, Art des Arbeitsvertrags, usw.) über alle Länder hinweg gleich ist.
- Random-Intercept-and-Slope-Modell (häufig auch verkürzt: Random-Slope-Modell): Dieses Modell wird gewählt, wenn die Annahme besteht, dass nicht nur die Gruppenmittelwerte, sondern auch der Einfluss mindestens eines Prädiktors zwischen den Ländern variiert. Insgesamt ermöglicht das Random-Slope-Modell eine differenziertere Analyse, wie länderspezifische Unterschiede (z.B. die Medienfreiheit im Mediensystem eines Landes) die abhängige Variable (wie Autonomie in der Nachrichtenselektion) über verschiedene Gruppen hinweg beeinflussen als das Random-Intercept-Modell. Es ist aber auch wesentlich komplexer und sollte deswegen nur verwendet werden, wenn man guten Grund zur Annahme hat, dass der Effekt einer unabhängigen Variablen nicht in allen Gruppen gleich ist.
Die endgültige Modellwahl sollte auf theoretischen Überlegungen fußen (weniger komplexe Modelle sind bei gleicher Erklärkraft stets vorzuziehen!), kann aber zusätzlich durch einen Likelihood-Ratio-Test begründet werden (siehe Schritt 7).
Schritt 5a: Ein Random-Intercept-Modell erstellen
Visualisierung des Modells
Die nachfolgende Abbildung visualisiert ein Random-Intercept-Modell, bei dem jedes Land einen eigenen Intercept (y-Achsenabschnitt) besitzt, der den jeweiligen „Landesmittelwert“ zum Berufseinstieg (0 Jahre) für die Autonomie in der Nachrichtenauswahl repräsentiert (sog. Random Intercept). Der Effekt der Berufserfahrung auf die Autonomie der Nachrichtenauswahl wird dagegen in allen Ländern als konstant angenommen, was an der konstanten Steigung der Regressionsgeraden zu erkennen ist. In Deutschland beispielsweise haben Berufsanfänger*innen deutlich weniger Autonomie in der Nachrichtenselektion als ihre Kolleg*innen aus anderen Ländern und auch wenn ihre Autonomie im Berufsleben zwar weiter zunimmt, überholen sie ihre Kolleg*innen aus anderen Ländern im Verlauf des Berufsleben auch nicht mehr.
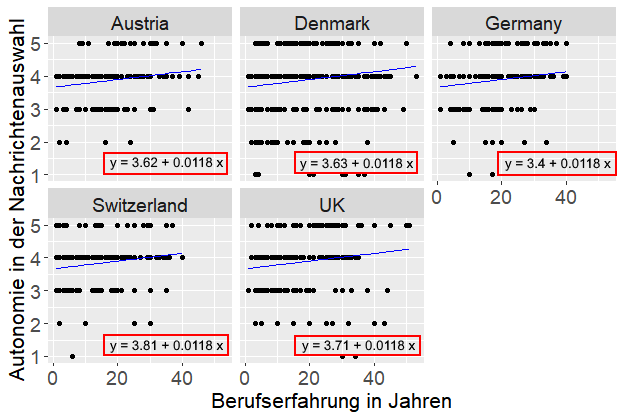
Berechnung in R
# RANDOM-INTERCEPT-MODELL
# Die abhängige Variable ist autonomy_selection
# Die unabhängigen Variablen sind work_experience, temp_contract und employment
# country wird als zufälliger Effekt für den Intercept berücksichtigt
random_intercept_model <- lmer(autonomy_selection ~ work_experience + temp_contract + employment + (1 | country), data = WoJ, REML = FALSE)
# Zusammenfassung des Modells anzeigen
summary(random_intercept_model)Erklärung der Formelbestandteile:
autonomy_selectionist Ihre abhängige Variable.- Das Tilde-Symbol
~trennt die abhängige Variable (auf der linken Seite) von den unabhängigen Variablen (auf der rechten Seite) in der Modellformel. Es ist eine Art von Zuweisung, die sagt: „Die linke Seite wird durch die rechte Seite erklärt oder vorhergesagt.“ - work_experience + temp_contract + employment beschreiben die Prädiktoren (d.h. erklärenden, unabhängigen Variablen) mit deren Hilfe die abhängige Variable erklärt werden soll.
+ (1 | country)fügt das Land als zufälligen Effekt hinzu. Dies bedeutet, dass wir zulassen, dass der Intercept für jedes Land unterschiedlich ist, was die Variation zwischen den Ländern berücksichtigt.REML = FALSEwählt die Maximum-Likelihood-Schätzung anstelle der Restricted Maximum Likelihood, was für Modellvergleiche sinnvoll ist.
Auswertung in R
Linear mixed model fit by maximum likelihood ['lmerMod']
Formula: autonomy_selection ~ work_experience + temp_contract + employment +
(1 | country)
Data: WoJ
AIC BIC logLik deviance df.resid
2255.2 2284.6 -1121.6 2243.2 984
Scaled residuals:
Min 1Q Median 3Q Max
-4.1914 -0.3004 0.1155 0.3997 1.9810
Random effects:
Groups Name Variance Std.Dev.
country (Intercept) 0.005772 0.07598
Residual 0.561251 0.74917
Number of obs: 990, groups: country, 5
Fixed effects:
Estimate Std. Error t value
(Intercept) 3.689990 0.059046 62.493
work_experience 0.013657 0.002273 6.007
temp_contractTemporary -0.102568 0.107306 -0.956
employmentPart-time -0.105600 0.074839 -1.411
Correlation of Fixed Effects:
(Intr) wrk_xp tmp_cT
work_exprnc -0.685
tmp_cntrctT -0.182 0.132
emplymntPr- -0.137 -0.022 0.003Interpretation der festen Effekte (Fixed Effects) im Random-Intercept-Modell:
- Intercept (y-Achsenabschnitt): Der Intercept gibt den geschätzten durchschnittlichen Wert der abhängigen Variable
autonomy_selectionan, wenn alle anderen Variablen auf Null gesetzt sind. Im vorliegenden Modell beträgt der Intercept-Wert 3.68, was darauf hindeutet, dass Journalist*innen im Durchschnitt eine relativ hohe Autonomie bei der Auswahl von Nachrichten haben. Der hohe t-Wert von 62.493 zeigt, dass dieser Intercept statistisch signifikant von Null verschieden ist. - work_experience: Der Koeffizient für
work_experienceist 0.013657. Dies deutet darauf hin, dass mit jedem zusätzlichen Jahr an Berufserfahrung die Autonomie bei der Auswahl von Nachrichten leicht zunimmt. Der positive t-Wert von 6.007 zeigt, dass dieser Effekt statistisch signifikant ist. - temp_contractTemporary und employmentPart-time: Bei der Analyse kategorialer Variablen in Regressionen, einschließlich MLMs, wird eine der Kategorien als Referenzkategorie festgelegt. Die Koeffizienten für die anderen Kategorien werden dann im Vergleich zu dieser Referenzkategorie interpretiert. Hier zeigen die negative Werte (-0.102568 für temporäre Verträge und -0.105600 für Teilzeitarbeit), dass solche Arbeitsverhältnisse im Vergleich zu unbefristeten Verträgen und Vollzeitarbeit mit einer geringeren Autonomie verbunden sind. Allerdings sind die t-Werte (-0.956 und -1.411) relativ niedrig, was darauf hindeutet, dass diese Effekte möglicherweise statistisch nicht signifikant sind.
Interpretation der zufälligen Effekte (Random Effects):
- country Intercept Variance und Standard Deviation: Die Varianz der zufälligen Effekte für Länder beträgt 0.005772 mit einer Standardabweichung von 0.07598. Dies zeigt, dass es Unterschiede in der Autonomie der Nachrichtenauswahl zwischen den Ländern gibt, diese Unterschiede jedoch relativ gering sind.
- Residual Variance und Standard Deviation: Die Residualvarianz beträgt 0.561251 mit einer Standardabweichung von 0.74917. Dies deutet darauf hin, dass ein signifikanter Teil der Variation in der Autonomie der Nachrichtenauswahl durch andere Faktoren als die Länderzugehörigkeit erklärt wird, was die Untersuchung weiterer Variablen rechtfertigt. Da sich die Residualvarianz im Vergleich zum Nullmodell verringert hat, wissen wir, dass unsere im Modell eingeführten Prädiktoren tatsächlich zusätzliche Varianz in der Autonomie der Nachrichtenauswahl erklären.
Interpretation der skalierten Residuen (Scaled Residuals) und die Informationen zur Passung des Modells:
- Skalierte Residuen: Die Werte reichen von Min -4.1914 bis Max 1.9810, mit Quartilen, die näher an Null liegen. Insgesamt deutet dies auf eine Verteilung die annähernd einer Normalverteilung folgt, aber der Min-Wert deutet auch auf potenzielle Ausreißer in den Daten hin.
- Informationen über die Passung des Modells: Für das Random-Intercept-Modell sind sowohl AIC als auch BIC niedriger als im Nullmodell. Das bedeutet, dass das Random-Intercept-Modell eine bessere Balance zwischen Modellpassung und Komplexität bietet. Zudem ist der Log-Likelihood weniger negativ und die Deviance niedriger im Random-Intercept-Modell als im Nullmodell. Dies deutet darauf hin, dass das Random-Intercept-Modell besser zu den beobachteten Daten passt, diese also besser modelliert / vorhersagt.
Berichten des Ergebnisses
„Nach der Analyse des Nullmodells, das aufgezeigt hat, dass ein gewisser Anteil der Varianz in der Autonomie der Nachrichtenauswahl zwischen den Ländern liegt, haben wir das Modell erweitert, um Prädiktoren zu berücksichtigen. Das Random-Intercept-Modell berücksichtigt nun die bisherige Berufserfahrung eines Journalisten, seine Vertragsart (befristet vs. unbefristet) und seinen Beschäftigungsstatus (Vollzeit vs. Teilzeit) als feste Effekte, während weiterhin die Variation zwischen den Ländern als zufälliger Effekt berücksichtigt wird. Es zeigt sich eine signifikante Verbesserung der Modellpassung im Vergleich zum Nullmodell. Dies wurde durch reduzierte AIC- (2255.2 vs. 2872.2) und BIC-Werte (2284.6 vs. 2887.5) sowie eine verbesserte Log-Likelihood (-1121.6 vs. -1433.1) und eine geringere Deviance (2243.2 vs. 2866.2) deutlich. Der positive Koeffizient für die Berugserfahrung (b = 0.013657, p < .05) impliziert einen signifikanten Anstieg der Autonomie in der Nachrichtenauswahl mit zunehmender Berufserfahrung. Negative, aber nicht signifikante Effekte wurden für temporäre Verträge (b = -0.102568) und Teilzeitarbeit (b = -0.105600) beobachtet, was auf potenzielle Einflüsse dieser Arbeitsbedingungen hindeutet.“
Schritt 5b: Ein Random-Intercept-and-Slope-Modell erstellen
Visualisierung des Modells
Die nachfolgende Abbildung visualisiert ein Random-Intercept-and-Slope-Modell, bei dem jedes Land einen eigenen Intercept (y-Achsenabschnitt) besitzt, der den jeweiligen „Landesmittelwert“ zum Berufseinstieg (0 Jahre) für die Autonomie in der Nachrichtenauswahl repräsentiert (sog. Random Intercept). Zusätzlich variiert der Effekt der Berufserfahrung auf die Autonomie der Nachrichtenauswahl von Land zu Land, was an der unterschiedlich starken Steigung der Regressionsgeraden zu erkennen ist (sog. Random Slope). In Deutschland beispielsweise haben Berufsanfänger*innen deutlich weniger Autonomie in der Nachrichtenselektion als ihre Kolleg*innen aus anderen Ländern. Im Verlauf ihres Berufsleben steigt ihre Autonomie dafür aber auch stärker an als in anderen Ländern, sodass ein deutscher Journalist mit 40 Jahren Berufserfahrung deutlich mehr Autonomie besitzt als ein dänischer Journalist mit 40 Jahren Berufserfahrung, obwohl der deutsche Journalist als Berufseinsteiger im Durschnitt weniger Autonomie besaß als sein dänischer Kollege.
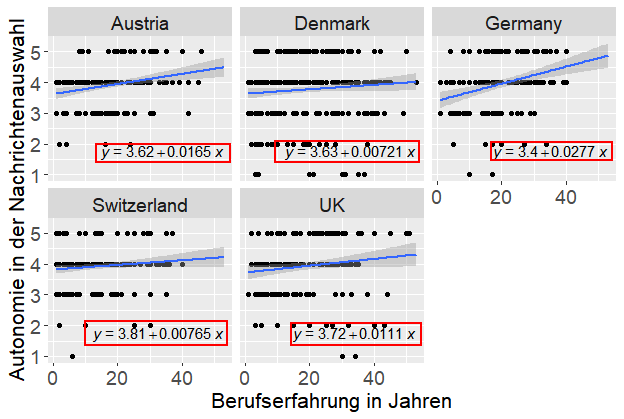
Berechnung in R
# RANDOM-INTERCEPT-AND-SLOPE-MODELL
# Die abhängige Variable ist autonomy_selection
# Die unabhängigen Variablen sind work_experience, temp_contract und employment
# country wird als zufälliger Effekt für den Intercept und den Slope (die Steigung der Regressionsgeraden) berücksichtigt
random_intercept_slope_model <- lmer(autonomy_selection ~ work_experience + temp_contract + employment + (1 + work_experience | country), data = WoJ)
# Zusammenfassung des Modells anzeigen
summary(random_intercept_slope_model)Erklärung der Formelbestandteile:
autonomy_selectionist Ihre abhängige Variable.- Das Tilde-Symbol
~trennt die abhängige Variable (auf der linken Seite) von den unabhängigen Variablen (auf der rechten Seite) in der Modellformel. Es ist eine Art von Zuweisung, die sagt: „Die linke Seite wird durch die rechte Seite erklärt oder vorhergesagt.“ - work_experience + temp_contract + employment beschreiben die Prädiktoren (d.h. erklärenden, unabhängigen Variablen) mit deren Hilfe die abhängige Variable erklärt werden soll.
(1 + work_experience | country)fügt sowohl zufällige Intercepts als auch zufällige Steigungen für die Variablework_experienceinnerhalb der Gruppecountryhinzu. Dies bedeutet, dass sowohl der Gruppenmittelwert (Intercept) vonautonomy_selectionals auch der Einfluss vonwork_experienceaufautonomy_selectionfür jedes Land unterschiedlich sein können. Das bedeutet: Das Modell berücksichtigt die Variation sowohl im Durchschnitt-Level der Autonomie als auch in der Beziehung zwischen Berufserfahrung und Autonomie über die verschiedenen Länder hinweg.REML = FALSEwählt die Maximum-Likelihood-Schätzung anstelle der Restricted Maximum Likelihood, was für Modellvergleiche sinnvoll ist.
Auswertung in R
Linear mixed model fit by maximum likelihood ['lmerMod']
Formula: autonomy_selection ~ work_experience + temp_contract + employment + (1 + work_experience | country)
Data: WoJ
AIC BIC logLik deviance df.resid
2258.2 2297.4 -1121.1 2242.2 982
Scaled residuals:
Min 1Q Median 3Q Max
-4.2115 -0.4627 0.1231 0.3836 1.9507
Random effects:
Groups Name Variance Std.Dev. Corr
country (Intercept) 0.0442075 0.21026
work_experience 0.0001069 0.01034 -0.94
Residual 0.5561538 0.74576
Number of obs: 990, groups: country, 5
Fixed effects:
Estimate Std. Error t value
(Intercept) 3.664942 0.106170 34.519
work_experience 0.014478 0.005173 2.799
temp_contractTemporary -0.114489 0.107329 -1.067
employmentPart-time -0.118770 0.074814 -1.588
Correlation of Fixed Effects:
(Intr) wrk_xp tmp_cT
work_exprnc -0.917
tmp_cntrctT -0.094 0.053
emplymntPr- -0.072 -0.011 0.011
optimizer (nloptwrap) convergence code: 0 (OK)
Model failed to converge with max|grad| = 1.36897 (tol = 0.002, component 1)Wie der letzten Zeile des R-Outputs zu entnehmen ist, erscheint die Warnung „Model failed to converge with max|grad| = 1.36897“. Sie ist ein Hinweis darauf, dass das Modell möglicherweise nicht korrekt konvergiert ist. Dies kann auf Probleme mit der Modellspezifikation, wie zu komplexe zufällige Effekte oder unzureichende Daten, hinweisen. Aufgrund der Konvergenzprobleme sollten Sie vorsichtig sein, die Ergebnisse des RISM zu interpretieren! Solche Probleme können die Gültigkeit der Modellschätzungen beeinträchtigen! In solchen Fällen ist es oft ratsam, sich auf ein einfacheres Modell wie das RI-Modell zu beschränken, besonders wenn dieses eine angemessene Passung bietet und keine Konvergenzprobleme aufweist. Es ist wichtig, in einem Bericht der Ergebnisse transparent über diese Entscheidung und die Gründe dafür zu berichten.
Berichten des Ergebnisses
„Nachdem das Random-Intercept-Modell eine signifikante Verbesserung der Modellpassung im Vergleich zum Nullmodell zeigte, haben wir ein Random-Intercept-and-Slope-Modell untersucht, um die mögliche Variation in den Effekten der Berufserfahrung zwischen den Ländern zu berücksichtigen. Da das Modell jedoch nicht konvergierte, was auf potenzielle Probleme in der Modellspezifikation wie zu komplexe zufällige Effekte hinweist, und eine hohe negative Korrelation (-0.94) zwischen den zufälligen Effekten für den Intercept und die Steigung der Berufserfahrung zusätzlich ein Identifikationsproblem1 anzeigt, haben wir uns entschieden, unsere Analyse und Interpretation auf das Random-Intercept-Modell zu beschränken, da es eine gute Erklärkraft bei geringer Komplexität liefert.“
Beachte: Ein sparsameres, weniger komplexes Modell mit weniger Parametern, das immer noch eine gute Passung bietet, ist stets vorzuziehen.
Schritt 6: Erweiterte Analysen und Interpretation
Hier könnten wir weitere Analysen durchführen, wie die Untersuchung von Interaktionseffekten, um tiefere Einblicke zu gewinnen. Zum Beispiel könnte man untersuchen, ob der Zusammenhang zwischen Berufserfahrung und Autonomie in der Nachrichtenselektion für Männer und Frauen unterschiedlich ist (z.B. weil männlichen Berufseinsteigern schon früher mehr Autonomie zugetraut wird oder vice versa).
In diesem Beispiel betrachten wir der Einfachheit halber jedoch ausschließlich Haupteffekte, da unsere H1 ohnehin keinen Interaktionseffekt annimmt.
Schritt 7: Modelle vergleichen
Nachdem wir das Random-Intercept-and-Slope-Modell nun ausgeschlossen haben, müssen wir noch prüfen, ob das Random-Intercept von der Passung des Modells auch tatsächlich signifikant besser ist als das weniger komplexe Nullmodell.
Berechnung in R
# MODELLVERGLEICH
anova(null_model, random_intercept_model)Dieser sogenannte Likelihood-Ratio-Test gibt einen Chi-Quadrat-Wert und einen p-Wert zurück. Ein kleiner p-Wert (< 0,05) zeigt an, dass das Random-Intercept-Modell eine signifikant bessere Passung als das Nullmodell bietet. Ein hoher p-Wert deutet darauf hin, dass die Hinzufügung der festen Effekte die Modellpassung nicht signifikant verbessert.
Tipp: Damit der Modellvergleich möglich ist, müssen alle zu testenden Modelle mit derselben Stichprobe berechnet worden sein. Deswegen lohnt es sich, den Datensatz gleich am Anfang der eigenen Arbeit so zu bereinigen, dass alle Variablen, die später als Prädiktoren genutzt werden sollen, im Datensatz keine fehlenden Werte (Missings = NA) mehr aufweisen. Das Nullmodell wird gleich mit diesem bereinigten Datensatz gefittet. Ein Beispiel für die Bereinigung sieht so aus:
WoJ <- tidycomm::WoJ %>%
filter(!is.na(work_experience) & !is.na(temp_contract) & !is.na(employment))Auswertung in R
Data: WoJ
Models:
null_model: autonomy_selection ~ 1 + (1 | country)
random_intercept_model: autonomy_selection ~ work_experience + temp_contract + employment + (1 | country)
npar AIC BIC logLik deviance Chisq Df Pr(>Chisq)
null_model 3 2289.2 2303.9 -1141.6 2283.2
random_intercept_model 6 2255.2 2284.6 -1121.6 2243.2 39.997 3 1.067e-08 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Die Analyse des Random-Intercept-Modells im Vergleich zum Nullmodell mithilfe des Likelihood-Ratio-Tests zeigt deutliche Unterschiede zwischen den beiden Modellen. Das Nullmodell, das nur einen zufälligen Effekt für die Länder berücksichtigt, hat 3 Parameter, einen AIC-Wert von 2289.2 und einen BIC-Wert von 2303.9. Demgegenüber weist das Random-Intercept-Modell, welches zusätzlich die Prädiktoren work_experience, temp_contract und employment umfasst, 6 Parameter auf und zeigt verbesserte AIC- und BIC-Werte von 2255.2 bzw. 2284.6. Dies deutet darauf hin, dass das Random-Intercept-Modell eine bessere Balance zwischen Modellpassung und Komplexität bietet.
Die Log-Likelihood, die ein Maß für die Passung des Modells an die Daten darstellt, ist im Random-Intercept-Modell weniger negativ (-1121.6) als im Nullmodell (-1141.6), was ebenfalls auf eine bessere Anpassung hinweist. Ebenso ist die Deviance im Random-Intercept-Modell mit 2243.2 niedriger als im Nullmodell, das eine Deviance von 2283.2 aufweist.
Der Likelihood-Ratio-Test, der einen Chi-Quadrat-Wert von 39.997 und einen extrem niedrigen p-Wert von 1.067e-08 bestätigt, dass die Hinzufügung der zusätzlichen Prädiktoren im Random-Intercept-Modell zu einer statistisch signifikanten Verbesserung der Passung führt. Diese Befunde legen nahe, dass das Random-Intercept-Modell eine signifikant bessere Erklärung für die Variation in der Autonomie bei der Nachrichtenauswahl bietet als das Nullmodell.
Berichten des Ergebnisses
„Ein Modellvergleich zeigt, dass das Random-Intercept-Modell (AIC = 2255.2, BIC = 2284.6, Log-Likelihood = -1121.6), welches Berufserfahrung, Art des Vertrags und Beschäftigungstatus als feste Prädiktoren einschließt, eine signifikant bessere Passung aufweist als das Nullmodell (AIC = 2289.2, BIC = 2303.9, Log-Likelihood = -1141.6). Der Likelihood-Ratio-Test ergab eine signifikante Verbesserung der Modellpassung (χ² = 39.997, df = 3, p < .001). Dies deutet darauf hin, dass die Berücksichtigung spezifischer Arbeitsmerkmale eine wesentliche Rolle bei der Erklärung der Autonomie in der Nachrichtenauswahl spielt und dieses Modell deswegen zur Beantwortung der Hypothese H1 herangezogen wird.“
Schritt 8: Bericht der Ergebnisse im Hinblick auf die Hypothese(n)
Schließlich werden die Ergebnisse im Kontext der ursprünglichen Hypothese diskutiert, wobei mögliche Einschränkungen und Implikationen für zukünftige Forschungen berücksichtigt werden (letzteres ggf. erst im Fazit / Diskussion des Berichts und noch nicht im Ergebnisteil).
Berichten des Ergebnisses
„Das Random-Intercept-Modell unterstützt die anfängliche Hypothese, dass Journalist*innen mit umfangreicher Berufserfahrung eine höhere Autonomie in der Auswahl von Nachrichten aufweisen. Der signifikante und positive Effekt der Berufserfahrung auf die Autonomie in der Nachrichtenauswahl (b = 0.013657, p < .05) ist konsistent mit der Annahme, dass erfahrenen Journalist*innen eher zugetraut wird, unabhängige Entscheidungen zu treffen. H1 kann somit angenommen werden.“
- Ein Identifikationsproblem in der Modellierung tritt auf, wenn ein Modell nicht genügend Informationen enthält, um die Parameter eindeutig zu schätzen. Es bedeutet, dass die vorhandenen Daten nicht ausreichen, um bestimmte Aspekte des Modells klar zu bestimmen. Das kann beispielsweise der Fall sein, wenn Multikollinearität vorliegt, also zwei oder mehr erklärende Variablen in einem Regressionsmodell stark korreliert sind, oder wenn die Datenmenge oder die Variation der Daten zu gering ist. Bei MLMs ist dies meist dann der Fall, wenn es zu wenige Gruppen gibt oder wenn die Gruppen nicht genügend Datenpunkte enthalten. ↩︎