
dplyr aktivieren
Stellen Sie zunächst sicher, dass das dplyr-Package mittels install.packages() installiert (nur ein einziges Mal installieren, aber denken Sie an die Anführungszeichen!) und mittels library() geladen ist. Da dplyr ein Package des tidyverse ist, reicht es aus, wenn Sie das gesamte tidyverse laden.
Package in R laden:
# install.packages("tidyverse")
library(tidyverse)Überblick über die 5 wichtigsten dplyr-Funktionen
- select(): Damit können aus einem bestehenden Datensatz bestimmte Variablen (Spalten) ausgewählt werden, um so die Breite des Datensatzes auf die interessierenden Variablen zu reduzieren. Die Spalten können nach Namen oder nach einem bestimmten Muster (z.B. mit starts_with, ends_with, contains) ausgewählt werden.
- filter(): Damit können aus einem bestehenden Datensatz bestimmte Fälle (Zeilen) basierend auf einer Filterbedingung herausgefiltert werden. Mehrere Bedingungen können kombiniert werden (logisches UND: &, logisches ODER: | )
- mutate(): Damit können Variablen (Spalten) hinzugefügt oder verändert werden, beispielsweise basierend auf einer mathematischen Umformungsbedingung.
- arrange(): Nicht im Datenanalyse-Seminar behandelt. Damit kann ein Datensatz auf Grundlage einer ausgewählten Variable nach der Größe auf- oder absteigend sortiert werden. Standardmäßig werden die Daten in aufsteigender Reihenfolge sortiert, aber mit desc() oder – auch in absteigender Reihenfolge möglich.
- summarise() / summarize(): Damit können wichtige statistische Kennzahlen berechnet werden, zum Beispiel Mittelwert und Standardabweichung. In Kombination mit group_by() können Kennzahlen für verschiedene Gruppen berechnet werden.
select()
Mit dem select()-Befehl werden aus einem bestehenden Datensatz bestimmte Variablen (Spalten) ausgewählt. Damit wird die Breite des Datensatzes auf die interessierenden Variablen reduziert.
Befehlsstruktur:
data %>%
select(variable1, variable2, ...)Zuerst wird der Datensatz definiert, auf den sich die Funktion beziehen soll, gefolgt von dem Pipe Operator (%>%). Mit select() können danach eine oder mehrere Spalten ausgewählt werden, wobei die Variablen mit einem Komma getrennt werden.
Beispiel:
Aus dem WoJ-Datensatz aus dem tidycomm-Paket wollen wir drei Variablen auswählen, die die Arbeitsbedingungen beschreiben (country, reach, employment). Diese drei Spalten speichern wir mit einem Zuweisungspfeil in dem neuen Objekt WoJ_conditions.
Befehl:
# Laden des WoJ Datensatzes
WoJ <- tidycomm::WoJ
WoJ_conditions <- WoJ %>%
select(country, reach, employment)Man kann den Inhalt des neuen Objektes und somit das Ergebnis des Codes abrufen, indem man „WoJ_conditions“ in der Konsole oder im Codefenster laufen lässt. Mit einem Doppelklick auf das Objekt WoJ_conditions in der Environment wird der vollständige, dreispaltige Datensatz angezeigt.
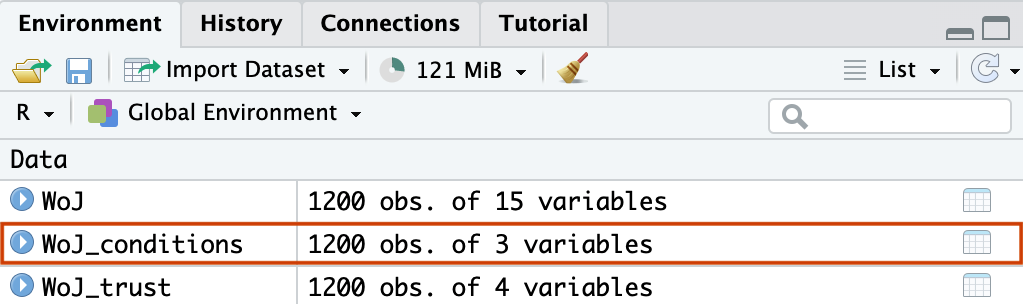
Das Ergebnis in der Konsole:
## WoJ_conditions
## # A tibble: 1,200 × 3
## country reach employment
## <fct> <fct> <chr>
## 1 Germany National Full-time
## 2 Germany National Full-time
## 3 Switzerland Regional Full-time
## 4 Switzerland Local Part-time
## 5 Austria National Part-time
## 6 Switzerland Local Freelancer
## 7 Germany Local Full-time
## 8 Denmark National Full-time
## 9 Switzerland Local Full-time
## 10 Denmark National Full-time
## # ℹ 1,190 more rows
Hilfsfunktionen:
Zu select()gibt es drei nützliche Hilfsfunktionen, die das Auswählen von speziellen, beispielsweise ähnlichen, Variablen erleichtern.
- starts_with(„String“): Auswahl von Spalten, die mit einem bestimmten String (= Zeichenkette) beginnen
- ends_with(„String“): Auswahl von Spalten, die mit einem bestimmten String (= Zeichenkette) enden
- contains(„String“): Auswahl von Spalten, die einen bestimmten String (= Zeichenkette) enthalten
Beispiel:
Aus dem WoJ-Datensatz wollen wir alle Variablen auswählen, in denen es um Vertrauen geht. Diese beginnen mit der Zeichenkette „trust_“ (trust_parliament, trust_parties, trust_government, trust_politicians).
Befehl:
WoJ_trust <- WoJ %>%
select(starts_with("trust_"))Wir erhalten vier Spalten in der Konsole:
## WoJ_trust
## # A tibble: 1,200 × 4
## trust_parliament trust_government trust_parties trust_politicians
## <dbl> <dbl> <dbl> <dbl>
## 1 3 3 3 3
## 2 4 4 3 3
## 3 4 4 3 3
## 4 4 4 3 3
## 5 3 2 2 2
## 6 4 4 3 2
## 7 2 1 3 2
## 8 4 3 3 3
## 9 1 1 1 1
## 10 3 3 3 3
## # ℹ 1,190 more rowsfilter()
Der filter()-Befehl filtert bestimmte Fälle (Zeilen) aus dem Datensatz heraus. Dazu wählt man eine Filtervariable aus, die eine Filterbedingung erfüllen soll.
Befehlsstruktur:
data %>%
filter(Filtervariable *Operator* "Filterbedingung")Es gibt verschiedene Operatoren, mit denen man die Filterbedingung formulieren kann:
- <: Kleiner gleich
- >: Größer gleich
- ==: Gleich
- !=: Ungleich
- <=: Kleiner gleich
- >=: Größer gleich
- %in%: Enthalten in (gefolgt von einem Vektor oder einer Liste mit möglichen Werten.)
- &: Und (verknüpft zwei Bedingungen. Beide müssen zutreffen.)
- |: Oder (verknüpft zwei Bedingungen. Mindestens eine muss davon zutreffen.)
Man kann eine oder mehrere Filterbedingungen setzen. Mehrere Bedingungen werden verknüpft. Wenn beide zutreffen sollen, werden die Filter mit einem & (Und) verbunden. Wenn mindestens eine der Filterbedingungen zutreffen soll, wird ein | (Oder) benutzt.
Beispiel 1:
Zuerst wollen wir nur eine Bedingung stellen. Es sollen Diejenigen aus dem WoJ-Datensatz ausgewählt werden, die in Vollzeit angestellt sind. Da man hier bestimmte Fälle (Zeilen) unter einer Bedingung (die Anstellungsart ist „Full-time“) auswählt, braucht man die Filterfunktion.
Achtung! Ein schneller Fehler kann bei dem Operator == (gleich) passieren. Hier sind zwei Gleichheitszeichen nötig!
Befehl:
WoJ %>%
filter(employment == "Full-time")## # A tibble: 902 × 15
## country reach employment temp_contract autonomy_selection
## <fct> <fct> <chr> <fct> <dbl>
## 1 Germany National Full-time Permanent 5
## 2 Germany National Full-time Permanent 3
## 3 Switzerland Regional Full-time Permanent 4
## 4 Germany Local Full-time Permanent 4
## 5 Denmark National Full-time Permanent 3
## 6 Switzerland Local Full-time Permanent 5
## 7 Denmark National Full-time Permanent 2
## 8 Austria Local Full-time Permanent 5
## 9 UK Regional Full-time Permanent 3
## 10 UK Transnational Full-time Permanent 4
## # ℹ 892 more rows
## # ℹ 10 more variables: autonomy_emphasis <dbl>, ethics_1 <dbl>, ethics_2 <dbl>, ethics_3 <dbl>, ethics_4 <dbl>, work_experience <dbl>,
## # trust_parliament <dbl>, trust_government <dbl>, trust_parties <dbl>, trust_politicians <dbl>Beispiel 2:
Nun wollen wir Fälle herausfiltern, die in den DACH-Ländern beschäftigt sind (also Schweiz, Österreich und Deutschland).
Befehl:
# Möglichkeit 1
WoJ %>%
filter(country == "Austria" | country == "Germany" | country == "Switzerland")
# Möglichkeit 2
WoJ %>%
filter(country %in% c("Austria", "Germany", "Switzerland"))Bei Möglichkeit 1 wird das logische ODER benutzt, da die Journalisten und Journalistinnen nur in einem der drei Länder beschäftigt sind.
Möglichkeit 2 prüft mit dem Operator %in% (enthalten in), ob der Wert in der Spalte „country“ des WoJ-Datensatzes in einem Vektor der Länder („Austria“, „Germany“, „Switzerland“) enthalten ist.
## # A tibble: 613 × 15
## country reach employment temp_contract autonomy_selection
## <fct> <fct> <chr> <fct> <dbl>
## 1 Germany National Full-time Permanent 5
## 2 Germany National Full-time Permanent 3
## 3 Switzerland Regional Full-time Permanent 4
## 4 Switzerland Local Part-time Permanent 4
## 5 Austria National Part-time Permanent 4
## 6 Switzerland Local Freelancer NA 4
## 7 Germany Local Full-time Permanent 4
## 8 Switzerland Local Full-time Permanent 5
## 9 Austria Local Full-time Permanent 5
## 10 Austria National Full-time Permanent 3
## # ℹ 603 more rows
## # ℹ 10 more variables: autonomy_emphasis <dbl>, ethics_1 <dbl>, ethics_2 <dbl>, ethics_3 <dbl>, ethics_4 <dbl>, work_experience <dbl>,
## # trust_parliament <dbl>, trust_government <dbl>, trust_parties <dbl>, trust_politicians <dbl>Beispiel 3:
Zuletzt sollen die Journalisten und Journalistinnen ausgewählt werden, die in Vollzeit arbeiten und gleichzeitig mindestens 10 Jahre Berufserfahrung haben. Hier wird das logische UND benutzt, da beide Bedingungen erfüllt sein müssen.
Da das Konsolen-Fenster sehr groß sein muss, um die Variable work_experience anzuzeigen, speichern wir den gefilterten Datensatz im neuen Objekt WoJ_filtered. Mit einem Doppelklick auf dieses Objekt in der Environment öffnet sich der gefilterte WoJ-Datensatz mit allen Variablen.
Befehl:
WoJ_filtered <- WoJ %>%
filter(employment == "Full-time" & work_experience >= 10) ## # A tibble: 644 × 15
## country reach. employment temp_contract autonomy_selection
## <fct> <fct> <chr> <fct> <dbl>
## 1 Germany National Full-time Permanent 5
## 2 Germany Local Full-time Permanent 4
## 3 Denmark National Full-time Permanent 3
## 4 Switzerland Local Full-time Permanent 5
## 5 UK Regional Full-time Permanent 3
## 6 Austria National Full-time Permanent 3
## 7 UK Transnational Full-time Permanent 4
## 8 Denmark National Full-time Permanent 4
## 9 Switzerland Regional Full-time Permanent 3
## 10 Denmark National Full-time Permanent 3
## # ℹ 634 more rows
## # ℹ 10 more variables: autonomy_emphasis <dbl>, ethics_1 <dbl>, ethics_2 <dbl>, ethics_3 <dbl>, ethics_4 <dbl>, work_experience <dbl>,
## # trust_parliament <dbl>,trust_government <dbl>, trust_parties <dbl>, trust_politicians <dbl>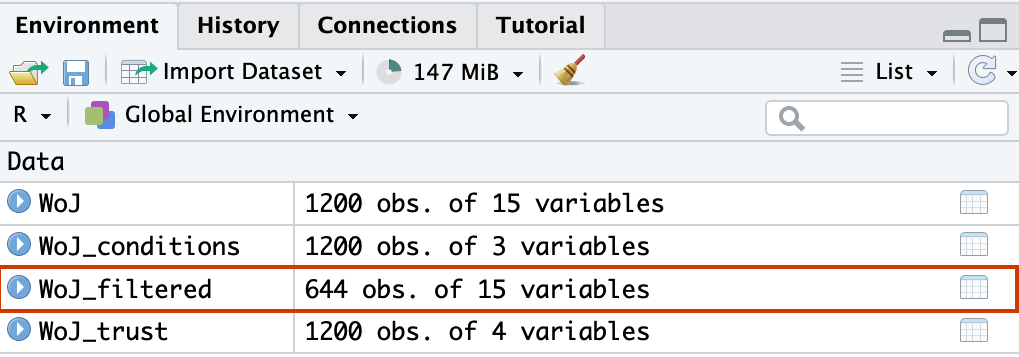
mutate()
Der mutate()-Befehl verändert oder erstellt Variablen. Mit der Funktion können bestehende Variablen aus einem Datensatz verändert und überspeichert werden oder neue Variablen hinzugefügt werden.
Befehlsstruktur:
data %>%
mutate(neuer_Variablenname = *Wert oder Umformbedingung*)Den Variablen kann entweder ein fester Wert (z.B. die Jahreszahl der Datenerhebung, sofern alle Daten im gleichen Jahr erhoben wurden) zugewiesen werden oder es wird ein Wert auf Basis des Werts einer bestehenden Variable für die (neue/veränderte) Variable generiert, z.B. mithilfe einer mathematischen Transformation (Letzteres kommt i.d.R. häufiger vor).
Beispiel 1:
Im WoJ-Datensatz gibt es zwei Variablen zur Autonomie (autonomy_selection, autonomy_emphasis). Aus diesen soll nun ein Summenindex gebildet werden, der in einer neuen Variable autonomy_mean gespeichert wird.
Um zu erkennen, ob die Transformation geklappt hat, lassen wir uns die drei Autonomie-Variablen mit der select()– Funktion anzeigen.
Befehl:
WoJ %>%
mutate(autonomy_mean = (autonomy_selection + autonomy_emphasis)) %>%
select(starts_with("autonomy"))## # A tibble: 1,200 × 3
## autonomy_selection autonomy_emphasis autonomy_mean
## <dbl> <dbl> <dbl>
## 1 5 4 9
## 2 3 4 7
## 3 4 4 8
## 4 4 5 9
## 5 4 4 8
## 6 4 4 8
## 7 4 4 8
## 8 3 3 6
## 9 5 5 10
## 10 2 4 6
## # ℹ 1,190 more rowsBeispiel 2:
Außerdem soll eine neue Variable im WoJ-Datensatz mit dem Variablennamen work_experience_month erstellt werden. Dafür muss die bestehende Variable work_experience, die die Berufserfahrung von Journalistinnen und Journalisten in Jahren angibt, so transformiert werden, dass darauf basierend die neue Variable die Berufserfahrung in Monaten angibt.
Danach sollen die beiden Variablen zur Berufserfahrung (einmal in Jahren, einmal in Monaten) ausgewählt werden, um die Transformation in der Ausgabe überprüfen zu können.
Befehl:
WoJ %>%
mutate(work_experience_months = work_experience * 12) %>%
select(starts_with("work_experience"))## # A tibble: 1,200 × 2
## work_experience work_experience_months
## <dbl> <dbl>
## 1 10 120
## 2 7 84
## 3 6 72
## 4 7 84
## 5 15 180
## 6 27 324
## 7 24 288
## 8 11 132
## 9 25 300
## 10 4 48
## # ℹ 1,190 more rowsarrange()
Mit der Funktion arrange() lassen sich Datensätze auf- und absteigend sortieren. Standardmäßig werden werden die Daten aufsteigend sortiert:
Befehlsstruktur:
data %>%
arrange(Variablenname)Die Daten können auch absteigend sortiert werden:
Befehl:
# Möglichkeit 1
data %>%
arrange(-Variablenname)
# Möglichkeit 2
data %>%
arrange(desc(Variablenname)Beispiel:
Wir wollen bestimmen, wie viele Jahre der Journalist oder die Journalistin mit der längsten Arbeitserfahrung bereits gearbeitet hat. Dazu sortieren wir die Variable work_experience absteigend. Außerdem zeigen wir uns mit dem select()– Befehl die Variable work_experience an, um sie gleich in der Konsole zu sehen.
Befehl:
WoJ %>%
arrange(-work_experience) %>%
select(work_experience)## # A tibble: 1,200 × 1
## work_experience
## <dbl>
## 1 53
## 2 51
## 3 50
## 4 50
## 5 49
## 6 46
## 7 45
## 8 45
## 9 45
## 10 45
## # ℹ 1,190 more rowsDie maximale Arbeitserfahrung liegt im WoJ-Datensatz bei 53 Jahren.
summarize() und group_by()
Die summarize()– Funktion bietet die Möglichkeit, statistische Kennzahlen zu berechnen. Dazu gehören Maximum, Minimum, Mittelwert, Standardabweichung und die Quantile. Es ist wichtig zu beachten, welche Berechnungen das Skalenniveau einer Variable zulässt.
Häufig wird summarize()zusammen mit group_by() benutzt. Die group_by()– Funktion gruppiert die Daten nach einer ausgewählten Variable. Nach der Anwendung dieser Gruppierungsfunktion können mithilfe von summarize()Berechnungen zu statistischen Kennwerten innerhalb jeder Gruppe durchgeführt werden.
Befehl:
data %>%
group_by(Gruppierungsvariable) %>%
summarize(
MAX = max(Variablenname, na.rm = TRUE), # Maximum
UQ = quantile(Variablenname, 0.75, na.rm = TRUE), # oberes Quartil
LQ = quantile(Variablenname, 0.25, na.rm = TRUE), # unteres Quartil
Mdn = median(Variablenname, na.rm = TRUE), # Median
M = mean(Variablenname, na.rm = TRUE), # Mittelwert
Mode = names(which.max(table(Variablenname))), # Modus
SD = sd(Variablenname, na.rm = TRUE), # Standardabweichung
MIN = min(Variablenname, na.rm = TRUE), # Minimum
count = n() # zählt Fälle
)Beispiel 1:
Zuerst wollen wir das untere und obere Quartil, Modus, Minimum und Maximum der Variable work_experience bestimmen.
Befehl:
WoJ %>%
summarize(
MAX = max(work_experience, na.rm = TRUE),
MIN = min(work_experience, na.rm = TRUE),
Mode = names(which.max(table(work_experience))),
LQ = quantile(work_experience, 0.25, na.rm = TRUE),
UQ = quantile(work_experience, 0.75, na.rm = TRUE)
)## # A tibble: 1 × 4
## MAX MIN Mode LQ UQ
## <dbl> <dbl> <chr> <dbl> <dbl>
## 1 53 1 10 8 25Beispiel 2:
Nun wäre es interessant, die Arbeitserfahrung von Journalisten und Journalistinnen mit der Reichweite ihres Mediums abzugleichen.
Dazu gruppieren wir die Daten nach der Variable reach (Reichweite des Mediums). Danach berechnen wir als statistische Kennzahlen den Mittelwert, den Median und die Standardabweichung der Variable work_experience für jede Gruppe. Außerdem lassen wir uns die Anzahl der Fälle pro Gruppe ausgeben.
Befehl:
WoJ %>%
group_by(reach) %>%
summarize(
Mdn = median(work_experience, na.rm = TRUE),
M = mean(work_experience, na.rm = TRUE),
SD = sd(work_experience, na.rm = TRUE),
count = n()
) Am Ergebnis erkennt man, dass für jede Gruppe der Variable reach (Local, Regional, National, Transnational) die Lagemaße der Variable work_experience berechnet wurden und die Anzahl der Fälle pro Gruppe angegeben wurde.
## # A tibble: 4 × 5
## reach Mdn M SD count
## <fct> <dbl> <dbl> <dbl> <int>
## 1 Local 20 18.6 10.7 149
## 2 Regional 18 18.4 11.2 355
## 3 National 16 17.4 10.9 617
## 4 Transnational 16 17.7 10.7 79