
In den Sozialwissenschaften werden Sie häufig mit umfangreichen Datensätzen konfrontiert, die eine Vielzahl von Fällen umfassen. Dies kann das Durchschauen und Verstehen der Daten erschweren. Visualisierungstechniken stellen daher eine effektive Lösung dar. Sie ermöglichen es, Datensätze entsprechend ihres Skalenniveaus angemessen zu visualisieren und statistische Analysen leichter interpretierbar zu machen. In diesem Abschnitt wird erläutert, wie Sie diese Prozesse in R mithilfe der Bibliotheken ggplot2 und tidycomm implementieren können.
ggplot2
Obwohl die Visualisierung mit Base R möglich und flexibel ist, zeigt sie bei komplexeren Grafiken oft ihre Grenzen aufgrund des hohen Aufwands. In solchen Fällen bietet ggplot2, ein zentrales Datenvisualisierungspaket aus dem tidyverse-Metapackage, eine effiziente Alternative. Dieses Paket basiert auf den Prinzipien der „Grammar of Graphics“ und ermöglicht es, mit einer einheitlichen Syntax verschiedene grafische Elemente in klar strukturierten Schichten zu organisieren und fein abzustimmen. Diese Methodik wird durch automatische Achsenanpassungen und erweiterte Funktionen wie die Skalierung von Ästhetiken (Farbe, Form, Größe), koordinatenspezifische Transformationen sowie die Erstellung von facettenreichen Plots weiter optimiert.
Installation und Einrichtung
Um ggplot2 zu verwenden, muss tidyverse installiert und dann in Ihrer R-Sitzung geladen sein:
# install.packages("tidyverse") # Installieren des tidyverse-Pakets - nur das erste Mal erforderlich
library(tidyverse) # Laden des PaketsKomponenten von ggplot2
In ggplot2 sind einige Grundelemente für jede Visualisierung unerlässlich: Daten, ästhetische Attribute und geometrische Objekte. Die Daten bilden die Basis jeder Grafik, ästhetische Attribute wie Farbe, Form und Größe definieren das Erscheinungsbild der Datenpunkte, und geometrische Objekte (wie Linien, Balken oder Punkte) bestimmen die Art der Darstellung. Darüber hinaus bietet ggplot2 eine Vielzahl von Erweiterungen, die es ermöglichen, die Visualisierungen weiter zu verfeinern und anzupassen. Hier ein Überblick:
| Komponent | Beschreibung | Beispiel Befehle |
|---|---|---|
| Daten | Der Datensatz, der visualisiert werden soll, üblicherweise als DataFrame oder Tibble. | ggplot(data = your_dataframe) |
| Aesthetics | Definiert die Zuordnung von Daten zu ästhetischen Attributen wie Achsenpositionierung, Farben, Formen und Größen zur Gruppenunterscheidung. | aes() |
| Geometries | Geometrische Objekte für die Darstellung der Daten, z.B. Kreise, Linien oder Balken. | geom_point(): Streudiagramm geom_bar(): Balkendiagramm geom_histogram(): Histogramm geom_boxplot(): Boxplot geom_line(): Linienplots |
| Scales | Anpassung der Darstellung der ästhetischen Attributen, z.B. Achseneinteilung. | scale_x_continuous() |
| Coordinate Systems | Bestimmt die Platzierung von geometrischen Objekten; standardmäßig kartesisch, mit Optionen wie Polar oder Achsenvertauschung. | coord_cartesian(), coord_polar(), coord_flip() |
| Facets | Aufteilung eines Plots in mehrere Panels, um Subgruppen der Daten zu zeigen. | facet_wrap(), facet_grid() |
| Themes | Gestaltung der nicht-datengebundenen Teile einer Grafik wie Hintergründe. | theme() |
| Labels | Ermöglicht die Anpassung von Textelementen wie Titeln, Achsenbeschriftungen und Legenden. | labs() |
| Statistical Transformations | Statistische Transformationen für Berechnungen und Darstellung von Datenzusammenfassungen. | stat_summary() |
Das Paket stellt zahlreiche weitere Funktionen zur Verfügung, die individuell angepasst werden können. Lassen Sie uns zunächst einen Blick auf einige dieser Komponenten werfen und untersuchen, wie sie mit dem bekannten WoJ-Datensatz in R verwendet werden können:
Befehl:
# Laden des WoJ Datensatzes
WoJ <- tidycomm::WoJ# Daten können mit dem Pipe-Operator übergeben werden
WoJ %>%
ggplot()Ausgabe:
Die Ausgabe ist ein leeres Koordinatensystem, das bereit ist, um durch weitere Schichten von geometrischen Objekten und ästhetischen Attributen ergänzt zu werden.

Sie erstellen nun eine Grafik, in der die Variable „employment“ auf der x-Achse und die Variable „work_experience“ auf der y-Achse dargestellt wird.
Befehl:
WoJ %>% #
ggplot(aes(x = employment, y = work_experience)) Ausgabe:
Diagrammtypen
Nun da Ihr Koordinatensystem und die Variablen feststehen, die Sie visualisieren möchten, können Sie einen Blick darauf werfen, wie unterschiedliche Diagrammtypen mithilfe von ggplot2 durch die Nutzung von geometrischen Objekten visualisiert werden können.
Boxplot
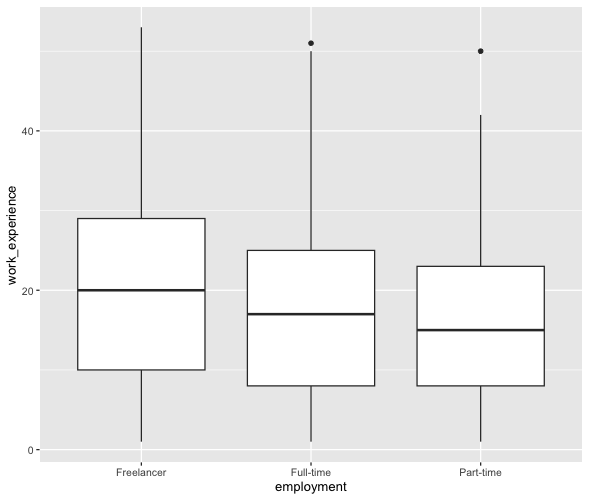
Lassen Sie uns einen Boxplot erstellen, indem Sie das passende geometrische Objekt spezifizieren.
Befehl:
WoJ %>%
ggplot(aes(x = employment, y = work_experience)) +
geom_boxplot()Ausgabe:
Dieses Vorgehen lässt sich analog auf andere Diagrammtypen übertragen, wobei die jeweilige Anzahl und Art der Variablen berücksichtigt werden muss: Streudiagramme benötigen zwei metrische Variablen und nutzen geom_point(). Balkendiagramme sind ideal für eine nominale Variable und verwenden geom_bar(), während Histogramme für eine einzelne metrische Variable mit geom_histogram() erstellt werden. Linienplots eignen sich für eine oder zwei metrische Variablen mittels geom_line(), und Boxplots, die mit geom_boxplot() erstellt werden, benötigen typischerweise eine nominale und eine metrische Variable.
Streudiagramm
Als Nächstes erstellen Sie ein Streudiagramm, das die Beziehung zwischen Arbeitserfahrung und Ethikbewertung visualisiert. Sie versehen die Grafik und die Achsen mit individuellen Beschriftungen und wenden ein spezielles Design-Thema an.
Befehl:
# Erstellen eines Streudiagramms mit Daten aus dem DataFrame WoJ
WoJ %>%
ggplot(aes(x = work_experience, y = ethics_1)) + # Definieren des Koordinatensystems bzw. der x- und y-Achse
geom_point() + # Hinzufügen von Punkten für jedes Datenpaar im Diagramm
labs(title = "Streudiagramm", # Festlegen des Titels des Diagramms
x = "Arbeitserfahrung", # Beschriftung der x-Achse
y = "Ethikbewertung 1") + # Beschriftung der y-Achse
theme_minimal() # Anwendung eines minimalen Themas für eine saubere VisualisierungAusgabe:

Balkendiagramm
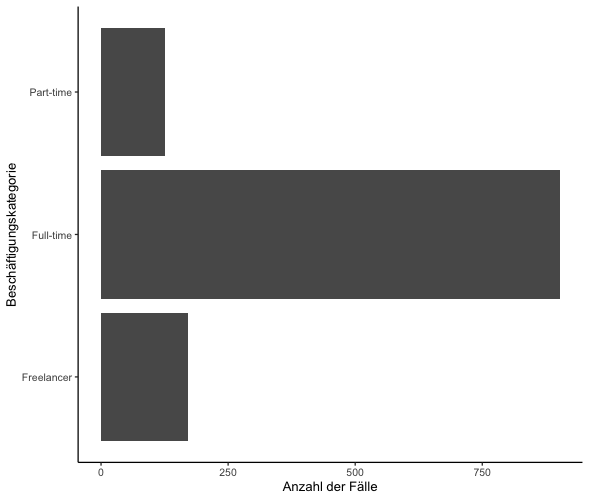
Nun erstellen Sie ein Balkendiagramm, um die Verteilung der Beschäftigungskategorien im WoJ-Datensatz zu visualisieren. Verwenden Sie dazu die Funktion geom_bar(), um die Häufigkeiten darzustellen, und setzen Sie coord_flip(), um das Diagramm horizontal zu orientieren. Zusätzlich wenden Sie das theme_classic() an, um der Grafik ein klassisches Design zu verleihen.
Befehl:
WoJ %>%
ggplot(aes(x = employment)) +
geom_bar() + # Hinzufügen der Balken, die die Häufigkeit der Kategorien darstellen
coord_flip() + # Drehen der Koordinaten, um die Balken horizontal anzuzeigen
labs(x = "Beschäftigungskategorie", y = "Anzahl der Fälle") + # Beschriftung der x- und y-Achsen
theme_classic() # Anwendung des klassischen ThemasAusgabe:
Histogramm
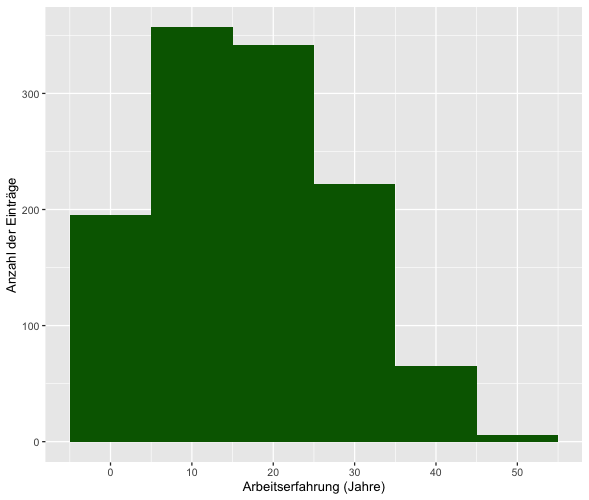
Sie erstellen ein Histogramm, um die Verteilung der Arbeitserfahrung im WoJ zu visualisieren. Die x-Achse ist über scale_x_continuous() so angepasst, dass sie die Jahre der Arbeitserfahrung zeigt, und die y-Achse, definiert durch scale_y_continuous(), gibt die Anzahl der Fälle an.
Befehl:
WoJ %>%
ggplot(aes(x = work_experience)) +
geom_histogram(binwidth = 10, fill = "darkgreen") + # Hinzufügen des Histogramms mit einer Binbreite von 10 und einer grünen Füllfarbe
scale_x_continuous(name = "Arbeitserfahrung (Jahre)", breaks = seq(0, 100, 10)) + # Anpassen der x-Achse
scale_y_continuous(name = "Anzahl der Einträge") Ausgabe:
tidycomm
Ein wesentliches Feature des tidycomm-Pakets ist der visualize()-Befehl, der es erleichtert, die Ergebnisse von Korrelationen, t-Tests, ANOVAs und ähnlichen statistischen Verfahren direkt und unkompliziert zu visualisieren. tidycomm bietet standardisierte Grafiktypen für jedes dieser Verfahren, sodass Sie nicht lange überlegen müssen, wie Sie die Ergebnisse eines Verfahren grafisch mittels ggplot2 darstellen möchten. Möchten Sie nahezu jeden Aspekt eines Diagramms steuern können, sollten Sie dagegen auf ggplot2 zurückgreifen und sich ihre Grafik selbst „zusammenbauen“.
Installation und Einrichtung
Zuerst muss sichergestellt werden, dass das Paket installiert und geladen ist.
Befehl:
# install.packages("tidycomm") # Installieren des tidycomm-Pakets - nur das erste Mal erforderlich
library(tidycomm)Visualisierung von Korrelation
Das tidycomm-Paket in R vereinfacht die Unterscheidung zwischen drei Korrelationstypen: die Visualisierung von Korrelationen zwischen zwei Variablen, zwischen mehreren Variablen und von partiellen Korrelationen. Für detaillierte Einblicke in diese Analysemethoden sei Ihnen das Kompendium zur Korrelation empfohlen.
Befehl:
WoJ %>%
correlate(ethics_1, autonomy_selection) %>%
visualize() # Visualisieren der Korrelation von zwei VariablenAusgabe:
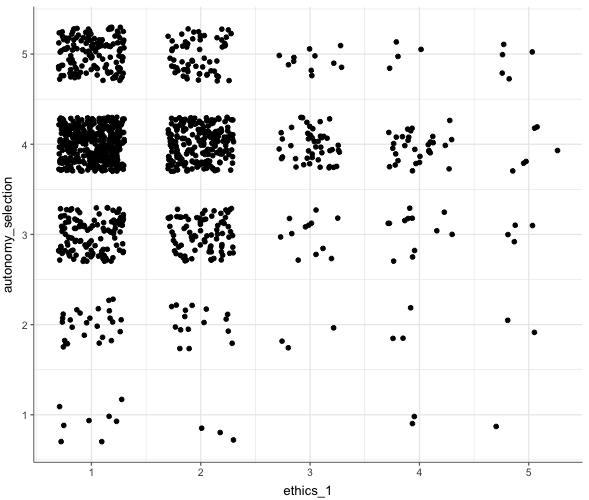
Befehl:
WoJ %>%
correlate(ethics_1, autonomy_selection, work_experience) %>%
visualize() # Visualisieren der Korrelation von mehreren VariablenAusgabe:
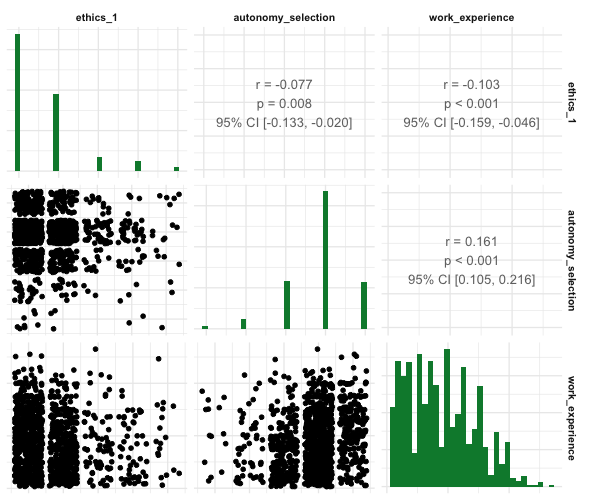
Befehl:
WoJ %>%
correlate(ethics_1, autonomy_selection, partial = work_experience) %>%
visualize() # Visualisieren einer partiellen KorrelationAusgabe:
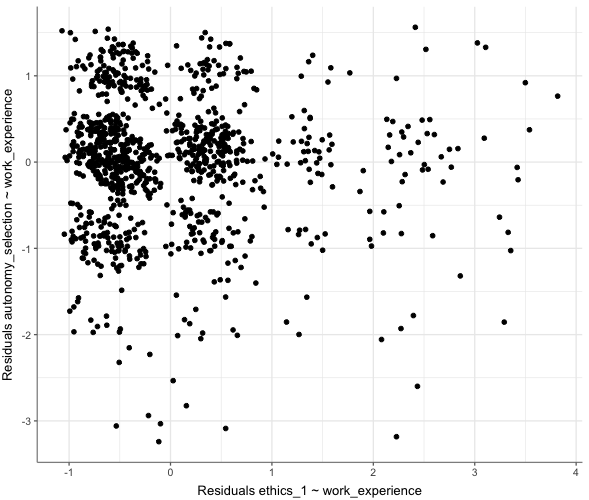
Visualisierung von t-Tests
Das tidycomm-Paket ermöglicht auch die Visualisierung von t-Test-Ergebnissen in R.
Befehl:
WoJ %>%
t_test(temp_contract, autonomy_selection) %>%
visualize()Ausgabe:
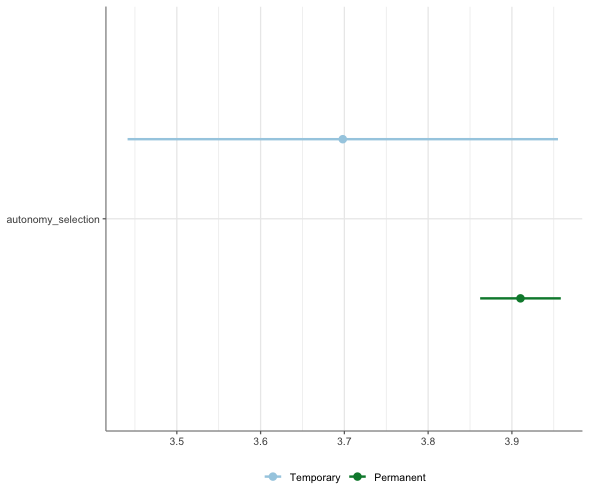
Visualisierung von ANOVAs
Befehl:
WoJ %>%
unianova(employment, autonomy_emphasis) %>%
visualize()Ausgabe:
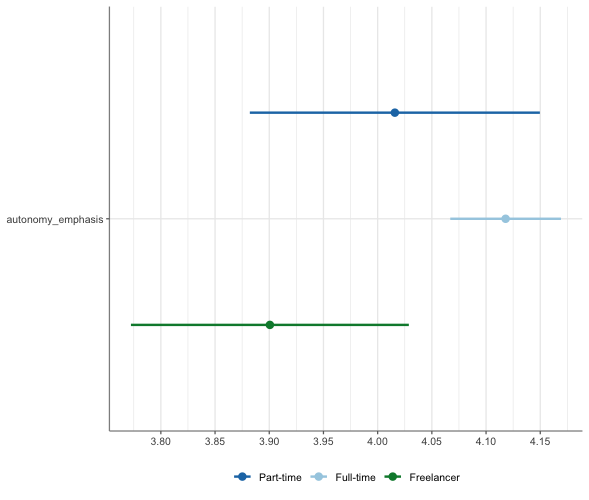
Visualisierung von Regressionen
Detaillierte Anleitungen zur Interpretation der Regressionsdiagramme und spezifische Informationen zur regress()-Funktion finden sich in unserem Kompendium zur Regression. Für direkte Hilfestellungen können zudem die Hilfebefehle ?visualize() und ?regress() in R konsultiert werden, die umfangreiche Erklärungen und Anwendungsbeispiele bieten.
Befehl:
WoJ %>%
regress(ethics_1, autonomy_selection, work_experience) %>%
visualize()Ausgabe:
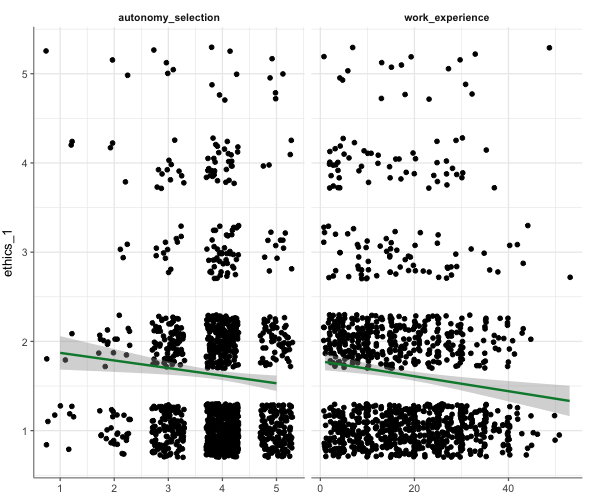
Befehl:
WoJ %>%
regress(ethics_1, autonomy_selection, work_experience) %>%
visualize(which = "correlogram")Ausgabe:
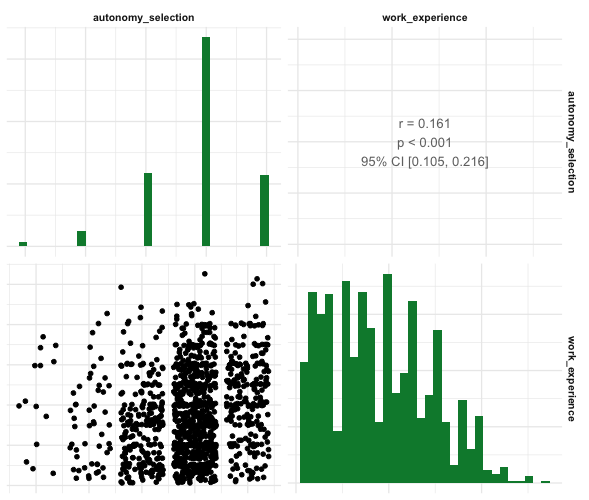
Befehl:
WoJ %>%
regress(ethics_1, autonomy_selection, work_experience) %>%
visualize(which = "resfit")Ausgabe:
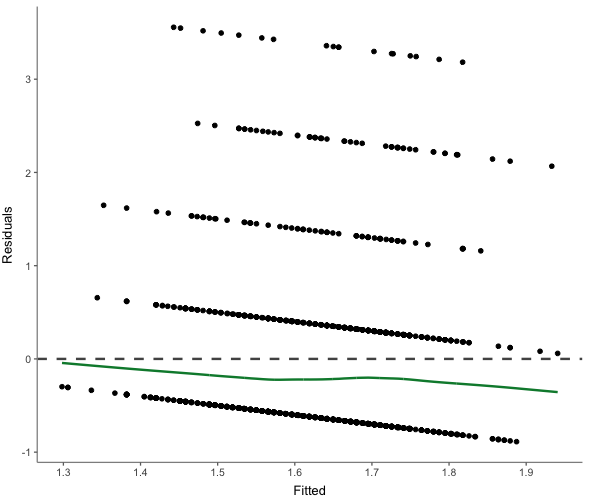
Befehl:
WoJ %>%
regress(ethics_1, autonomy_selection, work_experience) %>%
visualize(which = "pp")Ausgabe:
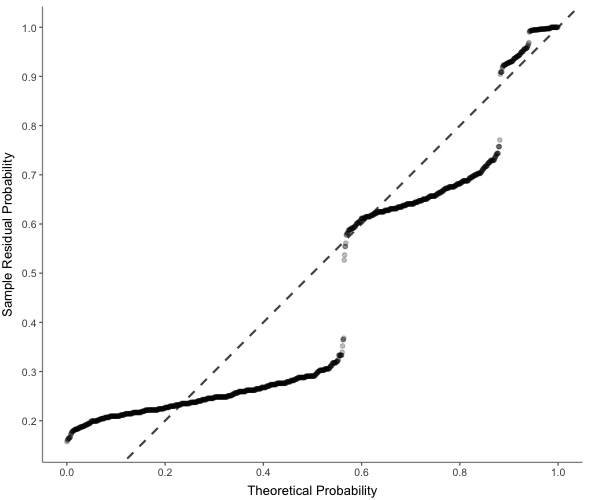
Befehl:
WoJ %>%
regress(ethics_1, autonomy_selection, work_experience) %>%
visualize(which = "scaloc")Ausgabe:
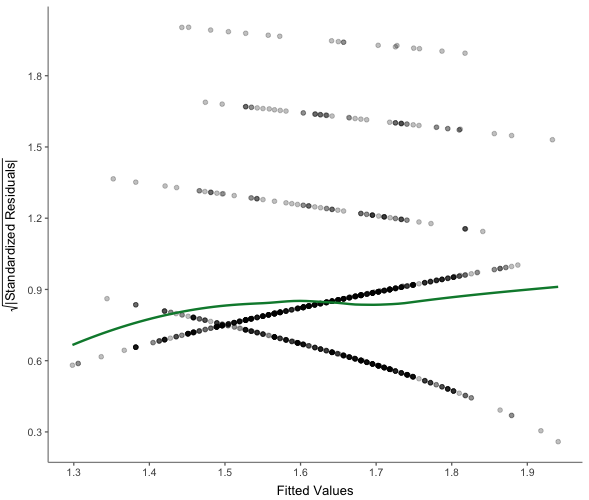
Hilfreicher Tipp: Farben in ggplot2
In R sind die Standardfarben wie Rot oder Blau für Datenvisualisierungen weit verbreitet. Es gibt jedoch oft ästhetisch und thematisch passendere Farben, die Ihre Daten besser zur Geltung bringen können. Diese Farben werden durch Hex-Codes repräsentiert.
| Farbname | Hex-Code |
|---|---|
| Aquamarin | #7FFFD4 |
| Koralle | #FF7F50 |
| Tiefes Himmelblau | #00BFFF |
| Gold | #FFD700 |
| Orchidee | #DA70D6 |
| Tomatenrot | #FF6347 |
| Seegrün | #2E8B57 |
| Siena | #A0522D |
| Lavendel | #E6E6FA |
| Limettengrün | #32CD32 |
Wenn Sie noch andere als die vordefinierten Farben verwenden möchten, können Sie Ihre eigenen auswählen, indem Sie den ästhetischen Parameter fill<code> über <code style="font-family: 'Courier New', monospace;">scale_fill_manual() beeinflussen. Hierbei wählen Sie manuell Ihre bevorzugten Farben aus. Lassen Sie uns eine praktische Anwendung in R durchführen, basierend auf dem Balkendiagramm, das wir oben erstellt haben.
Befehl:
WoJ %>%
ggplot(aes(x = employment, fill = employment)) +
geom_bar() +
coord_flip() +
labs(x = "Beschäftigungskategorie", y = "Anzahl der Fälle") +
scale_fill_manual(values = c("#FF6347", "#7FFFD4", "#4682B4")) + # Manuelle Farbzuweisung
theme_classic() Ausgabe:
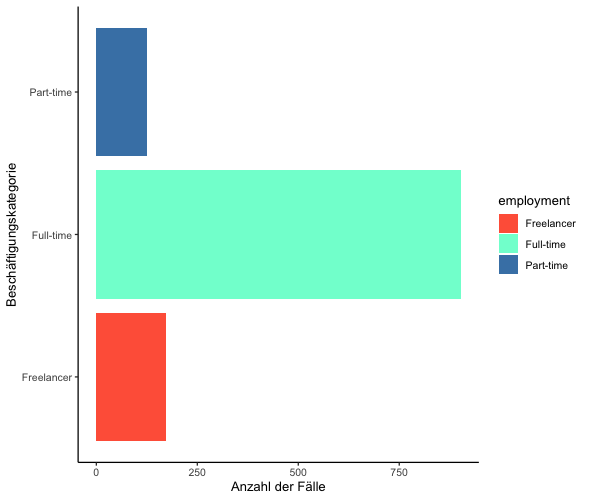
Bonus: Kreisdiagramm mit ggplot2
Balkendiagramme werden in der Regel aufgrund der besseren Vergleichbarkeit der Häufigkeitsverteilungen gegenüber Kreisdiagrammen zur Visualisierung von nominalen und ordinalen Variablen bevorzugt. Sollten Sie dennoch daran interessiert sein, ein Kreisdiagramm zu erstellen, haben Sie hier eine kurze Anleitung.
Befehl:
# Daten nach Beschäftigungsstatus gruppieren und Prozente berechnen
WoJ_Kreis <- WoJ %>%
group_by(employment) %>%
summarise(Anzahl = n()) %>%
mutate(Prozent = Anzahl / sum(Anzahl) * 100)
# Kreisdiagramm erstellen mit ggplot2, inklusive Prozentsätze und Pastel-Farbschema
ggplot(WoJ_Kreis, aes(x = "", y = Prozent, fill = employment)) +
geom_bar(stat = "identity", width = 1) +
coord_polar(theta = "y") + # Umwandlung in Kreisdiagramm
labs(title = "Verteilung der Beschäftigungsverhältnisse", fill = "Beschäftigungsstatus") +
scale_fill_brewer(palette = "Pastel1") + # Farbschema wählen
geom_text(aes(label = sprintf("%.1f%%", Prozent)), position = position_stack(vjust = 0.5)) + # Beschriftung der Segmente mit Prozentwerten
theme_void() # Entfernt Achsen und GitterlinienAusgabe:
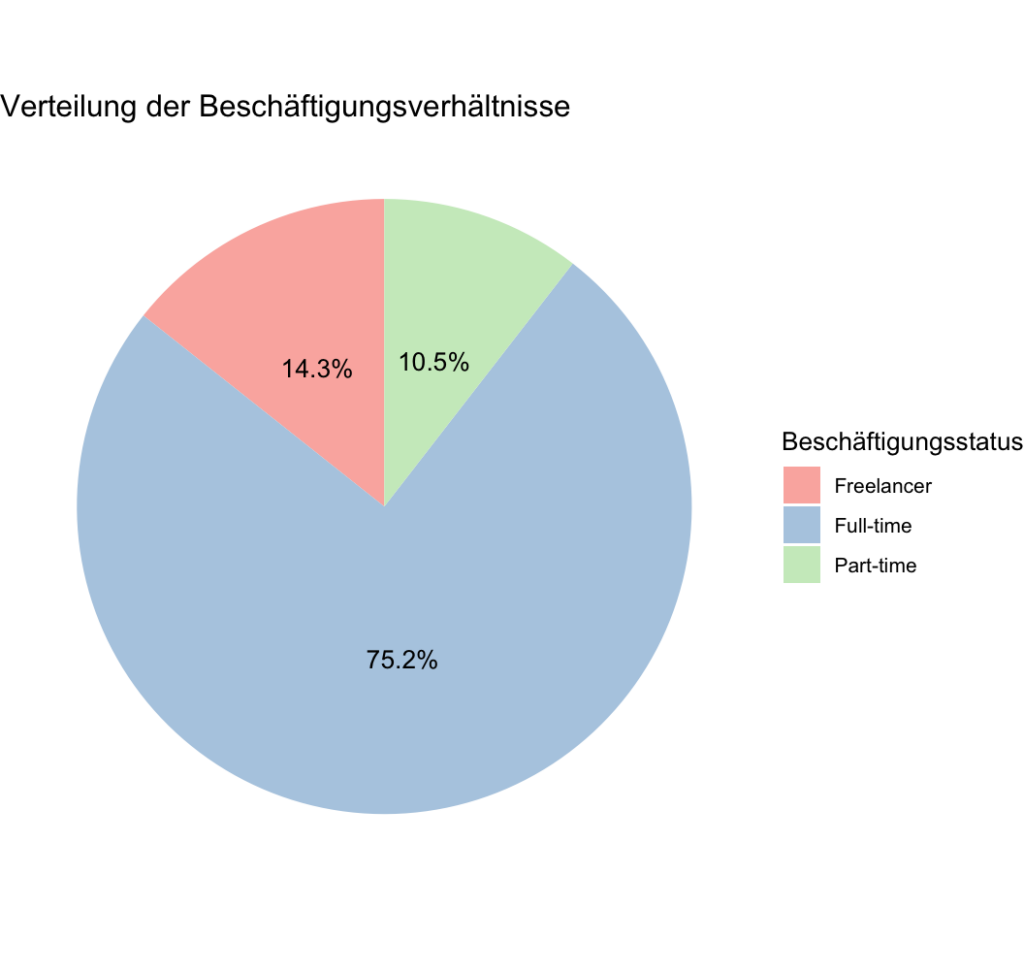
Das resultierende Kreisdiagramm zeigt die Verteilung der Beschäftigungsverhältnisse in Prozent. Jedes Segment des Diagramms repräsentiert einen Beschäftigungsstatus (Freelancer, Vollzeit, Teilzeit), und die Größe jedes Segments entspricht dem Prozentsatz der Individuen in jeder Kategorie.
Lehrmaterialien
Datenvisualisierung mit ggplot2 und tidycomm.