
Einführung in die Inhaltsanalyse
Dieses Tutorial bietet Ihnen eine theoretische sowie praktische Einführung in die Inhaltsanalyse, indem es die wichtigsten Schritte von der Idee bis zur Umsetzung erklärt – also von der Entwicklung einer Forschungsfrage, über die Erstellung eines Kategoriensystems und Codebuchs bis hin zur Codierung von Texten und Berechnung der Intercoderreliabilität mithilfe von R.
Definition der Inhaltsanalyse
„Content Analysis is a research technique for the objective, systematic, and quantitative description of the manifest content of communication.“ (Berelson, 1952)
Nach Berelson (1952) ist die Inhaltsanalyse eine „Forschungsmethode zur objektiven, systematischen und quantitativen Beschreibung des manifesten Inhalts von Kommunikation“. Dieser Ansatz hebt die Notwendigkeit hervor, Informationen quantitativ und objektiv zu erfassen, um zu belastbaren Ergebnissen zu kommen.
Merten (1983) erweitert diese Definition, indem er beschreibt, dass die Inhaltsanalyse oft dazu verwendet wird, „von Merkmalen eines manifesten Textes auf Merkmale eines nicht manifesten Kontextes“ zu schließen. Damit wird deutlich, dass Inhaltsanalysen nicht nur darauf abzielen, manifeste Inhalte zu erfassen, sondern auch die tieferliegenden sozialen Strukturen und Bedeutungen zu entschlüsseln.
„Inhaltsanalyse ist eine Methode zur Erhebung sozialer Wirklichkeit, bei der von Merkmalen eines manifesten Textes auf Merkmale eines nicht manifesten Kontextes geschlossen wird.“(Merten, 1983)
„Die Inhaltsanalyse ist eine empirische Methode zur systematischen, intersubjektiv nachvollziehbaren Beschreibung inhaltlicher und formaler Merkmale von Mitteilungen; (häufig mit dem Ziel einer darauf gestützten interpretativen Inferenz).“ (Früh, 2004)
Früh (2004) beschreibt die Methode als systematisch* sowie intersubjektiv nachvollziehbar** und betont ebenfalls, dass sie häufig dazu dient, auf der Basis der Analyse Interpretationen über gesellschaftliche Phänomene abzuleiten.
* Systematisch bedeutet, dass die Inhaltsanalyse nach einem strukturierten und methodischen Plan erfolgt, um willkürliches Vorgehen oder zufällige Interpretationen zu vermeiden. Im Detail heißt das: 1) Regeln und Verfahren werden im Vorfeld festgelegt, z.B. wie Texte ausgewählt und welche Kategorien analysiert werden. 2) Jede Textstelle oder Information wird nach denselben Kriterien untersucht und bewertet, unabhängig davon, wer die Analyse durchführt oder wie oft sie wiederholt wird. 3) Es gibt eine festgelegte Reihenfolge, wie die Analyse vonstattengeht – angefangen von der Datenauswahl über die Codierung bis zur Auswertung.
** Intersubjektiv nachvollziehbar bedeutet, dass die Vorgehensweise und die Ergebnisse der Inhaltsanalyse so gestaltet sein müssen, dass sie für verschiedene Personen (Subjekte) verständlich und reproduzierbar sind. Anders gesagt: Wenn verschiedene Forscher:innen die gleichen Materialien unter denselben methodischen Bedingungen analysieren, sollten sie zu ähnlichen Ergebnissen kommen. Dies setzt voraus, dass: 1) Die Methodik transparent dokumentiert ist, sodass andere Forscher:innen nachvollziehen können, wie die Analyse durchgeführt wurde (z.B. durch genaue Definition von Kategorien und Codierregeln). 2) Die Kategorien und Codierregeln beim Codieren eindeutig und konsistent angewendet werden, um Interpretationsspielraum so gering wie möglich zu halten. 3) Die Ergebnisauswertung nicht auf subjektiven Meinungen der Forschenden basiert, sondern auf klaren Kriterien, wo immer möglich (wie z.B. Intercoderreliabilitätstests und Häufigkeitsverteilungen).
Erkenntnisziele der Inhaltsanalyse
Basierend auf den oben präsentierten Definitionen können wir festhalten, dass das primäre Ziel der Inhaltsanalyse die systematische Beschreibung von Kommunikationsinhalten ist (= Deskription), um Rückschlüsse auf soziale Kontexte, gesellschaftliche Entwicklungen oder kommunikationsstrategische Ziele zu ziehen (= Inferenz). Zum Beispiel könnte eine Analyse von Nachrichtenartikeln zur Terrorberichterstattung Aufschluss darüber geben, wie gesellschaftliche Angst erzeugt wird oder welche Akteure in der medialen Darstellung von Terrorismus besonders hervorgehoben werden, also häufiger unter Terrorverdacht gestellt werden.
Einordnung in die Methoden der Sozialforschung
Die Inhaltsanalyse ist eine von mehreren Methoden der empirischen Sozialforschung. Sie steht neben anderen etablierten Verfahren wie Befragungen, Experimenten oder Beobachtungen. Der zentrale Unterschied liegt dabei in der Art des untersuchten Materials: Während Befragungen subjektive Einschätzungen und Meinungen durch Interviews oder Fragebögen erheben, konzentriert sich die Inhaltsanalyse auf bereits vorhandene, statische Daten – wie Texte, politische Reden oder audiovisuelle Medien – und arbeitet nach strengen Regeln, um deren Bedeutung zu entschlüsseln.
Vorteile und Nachteile der Inhaltsanalyse
Ein großer Vorteil der Inhaltsanalyse ist, dass das untersuchte Material nicht durch den Erhebungsprozess selbst beeinflusst wird. Bei Befragungen oder Interviews kann die Art und Weise, wie Fragen gestellt werden, die Antworten verfälschen, indem die Befragten beeinflusst werden, was zu einer Verzerrung der Antworten führen kann. Die Inhaltsanalyse hingegen greift auf bereits existierende Daten zurück, deren Inhalt sich nicht durch die Untersuchung verändert. Außerdem gilt der Grundsatz ‚Papier ist geduldig, Menschen nicht‘ – während Interviewpartner:innen spontan absagen können, steht Ihnen das untersuchte Material bei der Inhaltsanalyse dauerhaft und zu jeder Zeit zur Verfügung. Das erlaubt eine vereinfachte Studienplanung bei Abschlussarbeiten. Kurz und knapp zusamemngefasst:
Vorteile:
- Objektivität: Die systematische Vorgehensweise erlaubt eine möglichst objektive Beschreibung der Inhalte.
- Reproduzierbarkeit: Die Analyse kann von anderen Forschenden nach denselben Kriterien durchgeführt und überprüft werden.
- Unabhängigkeit: Texte stehen in der Regel dauerhaft zur Verfügung und verändern sich nicht durch den Analyseprozess.
- Effizienz: Große Mengen an Texten können durch technologische Hilfsmittel wie R effektiv analysiert werden.
Nachteile:
- Interpretationsspielraum: Besonders bei latenten Merkmalen ist häufig Interpretation erforderlich, was zu geringerer intersubjektiver Nachvollziehbarkeit führen kann, wenn die Dokumentation des Vorgehens nicht ausführlich und präzise ausfällt.
- Kein direkter Kontakt: Anders als bei Befragungen können keine Rückfragen an die Ersteller:innen der Texte gestellt werden, um Unklarheiten oder Missverständnisse aufzulösen.
- Eingeschränkter Zugang: Nicht immer stehen die zu analysierenden Texte frei zur Verfügung und Zugangsbeschränkungen (z.B. Urheber- und Lizenzrechte) können sie unmöglich machen.
Beispielhafte inhaltsanalytische Forschungsfragen
Mit der Inhaltsanalyse lassen sich vielfältige Fragestellungen bearbeiten, z.B.:
- Wie häufig werden bestimmte Themen (z.B. rechtsextrem-motivierter vs. linksextrem-motivierter Terrorismus) in der Berichterstattung behandelt?
- Welche Akteure (z.B. Expert:innen, Opfer, Täter:innen) kommen in der medialen Darstellung von Ereignissen vor?
- Wie emotional oder neutral ist die Berichterstattung über ein bestimmtes Thema?
Beispielhafter Ablauf einer Inhaltsanalyse
Die Durchführung einer Inhaltsanalyse lässt sich in mehrere Schritte unterteilen:
- Entwicklung des Kategoriensystems: Hier werden die zentralen Merkmale festgelegt, nach denen Texte analysiert werden. Dies geschieht oft auf Basis theoretischer Überlegungen oder durch qualitative Exploration des Materials.
- Codebuch und Codierschulung: Ein detailliertes Codebuch wird erstellt, das die Kategorien und Variablen definiert udn operationalisiert. Codierer:innen werden geschult, um eine hohe Reliabilität zu gewährleisten.
- Pretest-Codierung: Eine allererste Codierung beziehungsweise Annotation der Texte findet statt, bei der die definierten Merkmale systematisch erfasst werden. Alle Codierer:innen sammeln Fälle, bei denen sie sich unsicher waren.
- Prüfung der Intercoder-Reliabilität: Um die Konsistenz der Codierungen sicherzustellen, wird die Übereinstimmung zwischen verschiedenen Codierer:innen überprüft, z.B. mit Krippendorffs Alpha. Basierend auf dem Feedback der Codierer:innen aus dem Pretest und den Reliabilitätsergebnissen wird das Codebuch überarbeitet, um die intersubjektive Nachvollziehbarkeit und Reproduzierbarkeit der Ergebnisse zu erhöhen.
- Verbesserung des Kategoriensystems: Schritte 3 und 4 werden solange wiederholt, bis sich bei dem Intercoder-Reliabilitätstests zufriedenstellende Reliabilitätswerte ergeben. Nun werden alle Texte basierend auf dem finalen Entwurf des Codebuchs codiert.
- Analyse und Interpretation: Die codierten Daten werden schließlich mittels R analysiert, d.h. statistisch ausgewertet und interpretiert.
Untersuchungseinheiten der Inhaltsanalyse
Auswahleinheit
Die Auswahleinheit bezeichnet das gesamte Spektrum verfügbaren Medienmaterials für die Untersuchung.
Beispiel: Alle Artikel über den Anschlag in München 2016, die in den ersten zwei Wochen nach dem Ereignis in den größten nationalen Tageszeitungen erschienen sind.
Analyseeinheit
Das spezifische Element aus dem Untersuchungsmaterial / der Auswahleinheit, das analysiert wird.
Beispiel: Der SZ-Artikel „Amoklauf von München: Wir twittern, als würden wir laut denken“ vom 1. Oktober 2016, 17:44 Uhr
Codiereinheit
Aspekte, die an dem Medienmaterial interessant sind, um die Forschungsfrage zu beantworten und durch die Kategorien adressiert werden
Beispiel: Tenor des Beitrags, Quelle des Artikels, Länge des Beitrags
Kontexteinheit
Die Kontexteinheit liefert den Zusammenhang, in dem die Codiereinheit betrachtet wird. Die Kontexteinheit beschreibt also den Textabschnitt, der zusätzlich herangezogen wird, um die Codierungseinheit richtig zu verstehen. Dies ist notwendig, weil manche Merkmale in einem isolierten Satz oder einer Phrase nicht verständlich sind oder ihre Bedeutung sich erst durch das Umfeld erschließt.
Beispiel: Es wird zusätzlich betrachtet, in welcher Rubrik der Zeitung der Artikel veröffentlicht wurde, also zum Beispiel im Politik-Teil, Lokal-Teil oder – bei tragischen Ereignissen wie Terroranschlägen natürlich mehr als unwahrscheinlich – im Satire-Teil
Entwicklung eines Kategoriensystems und Codebuchs
Ein gut strukturiertes Kategoriensystem ist das Herzstück jeder Inhaltsanalyse. Es sorgt dafür, dass die Analyse systematisch, strukturiert und intersubjektiv nachvollziehbar durchgeführt werden kann. Das bedeutet, dass die Kategorien, nach denen der Text untersucht wird, klar definiert sind und von verschiedenen Personen auf die gleiche Weise angewendet werden können.
Deduktive und induktive Kategorien
Beim Erstellen eines Kategoriensystems können die Kategorien entweder deduktiv (theoriegeleitet) oder induktiv (aus dem Material heraus) abgeleitet werden.
- Deduktive Kategorien: Diese werden im Voraus festgelegt und basieren auf bestehenden Theorien. Wenn man zum Beispiel die Darstellung von Emotionen in Texten analysieren möchte, könnte man Kategorien wie „Wut“, „Freude“, „Angst“ usw. bereits im Vorfeld basierend auf der Cognitive Appraisal Theory of Emotion definieren und anschließend nach diesen Emotionen im Text suchen. Deduktive Kategorien bieten den Vorteil, dass sie auf theoretischen Grundlagen fußen und sehr zielgerichtet genutzt werden können, um die zuvor festgelegten Hypothesen zu beantworten.
- Induktive Kategorien: Diese werden während der Analyse direkt aus dem Material heraus entwickelt, oft durch eine vorausgehende qualitative Analyse des Materials. Das bedeutet, dass man offen an die Analyse herangeht und neue Themen oder Muster identifiziert, die sich im Text ergeben. Diese Vorgehensweise erlaubt es, Überraschendes oder bislang Unbekanntes zu entdecken. Sie eignet sich besonders gut für explorative Untersuchungen, bei denen wenig Vorwissen über das Thema vorhanden ist.
Manifeste und latente Kategorien
Außerdem können die Kategorien entweder manifeste (direkt im Text erkennbare, eindeutige) oder latente (versteckte, interpretative) Textmerkmale erfassen. Dementsprechend sprechen wir von manifesten und latenten Kategorien.
- Manifeste Kategorien zu erheben bedeutet, dass man genau das untersucht, was im Text sichtbar und eindeutig ist, wie zum Beispiel bestimmte Wörter, die explizit genannt werden.
- Latente Kategorien versuchen im Gegensatz dazu die tieferliegenden, verborgenen Bedeutungen erfassen, die hinter den Worten stehen – etwa Motive, Absichten oder Emotionen, die nicht direkt genannt, aber zwischen den Zeilen erkennbar sind. Wenn man in einem Text das latente Merkmal „Liebe“ untersucht (ohne zählen zu wollen, wie oft das Wort „Liebe“ explizit genannt wird), könnte man bestimmte Handlungen, Gesten oder emotionale Beschreibungen identifizieren, die auf Liebe hindeuten. Durch die Inhaltsanalyse könnte man dann diese latenten Merkmale durch messbare Indikatoren erfassen – etwa „zärtliche Handlungen“, „emotionale Nähe“ oder „Opferbereitschaft“.
Ein beispielhaftes Kategoriensystem
Das Kategoriensystem ist die Organisationsstruktur, die alle relevanten Merkmale (Kategorien) definiert, die in einem Text oder Untersuchungsmaterial erfasst werden sollen (antwortet auf die Frage: Was wird untersucht?). Es besteht also aus den verschiedenen Kategorien, die entweder theoriegeleitet oder aus dem Material heraus entwickelt wurden. Dieses System gibt vor, welche Merkmale oder Inhalte betrachtet und analysiert werden. Die Kategorien sollten deswegen klar definiert und eng an der Forschungsfrage ausgerichtet sein.
Das Codebuch ist detaillierter und operationalisiert die Kategorien des Kategoriensystems (antwortet auf die Frage: Wie wird untersucht?). Das heißt, dass es genau beschreibt, wie diese Kategorien auf den Text angewendet werden sollen, welche Kriterien für die Zuordnung zu einer Kategorie relevant sind, und welche Regeln die Codierenden dabei befolgen müssen. Es enthält zudem Anweisungen und Ankerbeispiele (= typische oder aber besonders knifflige Beispiele und deren Erläuterung), um sicherzustellen, dass die Codierung konsistent und intersubjektiv nachvollziehbar erfolgt.
Lassen Sie uns am Beispiel des Datensatzes aus tidycomm::fbposts veranschaulichen, wie ein solches Codebuch aussehen könnte:
| Variable | Bescheibung | Wertebereich | Codes/ID |
|---|---|---|---|
| post_id | Unique ID of the coded Facebook post | NUMERIC | 1,2,3 … |
| coder_id | ID of the coder | NUMERIC | 1= Coder 1 2= Coder 2 3= Coder 3 4= Coder 4 5= Coder 5 6= Coder 6 |
| type | Type of the Facebook post | CATEGORICAL | „link“, „photo“, „status“, „video“ |
| n_pictures | Number of pictures attached to the post, ranges from 0 to 6 | NUMERIC | 0,1,2… |
| pop_elite | Populism indicator; aims to answer the research question: Does the post attack elites? | CATEGORICAL | 0 = no attacks on elites 1 = attacks political actors 2 = attacks public administration actors 3 = attacks economic actors 4 = attacks media actors/journalists 9 = attacks other elites |
| pop_people | Populism indicator; aims to answer the research question: Does the post refer to ‚the people‘? | BINARY | 0 = does not refer to ‚the people‘ 1 = refers to ‚the people‘ |
| pop_othering | Populism indicator; aims to answer the research question: Does the post attack ‚others‘? | CATEGORICAL | 0 = no attacks on ‚others‘ 1 = attacks other cultures 2 = attacks other political stances 3 = attacks other ‚others‘ |
Es ist wichtig anzumerken, dass die Kategorien normalerweise noch detaillierter beschrieben werden, um Missverständnisse unter den Codierer:innen zu vermeiden. Insbesondere fehlen in dem hier präsentierten, sehr simplen Codebuch Ankerbeispiele, um Codierer:innen eine klare Orientierung zu geben, wie bestimmte (Ausnahme-)Fälle zu codieren sind.
Schritte zur Erstellung eines Codebuchs
Die Erstellung eines Codebuchs erfolgt in mehreren Schritten:
- Theoriearbeit, Erstellung einer Forschungsfrage (und gegebenenfalls zugehöriger Hypothesen): Bevor das Kategoriensystem erstellt wird, ist es entscheidend, eine solide theoretische Grundlage zu schaffen. Hierzu gehört die Entwicklung einer Forschungsfrage, die beschreibt, was untersucht werden soll. Die Theoriearbeit ermöglicht es, die relevanten Konzepte zur Beantwortung dieser Forschungsfrage aus der Literatur zu identifizieren und in Schritt 2 zur Erstellung des Kategoriensystems verwenden zu können. Für Sie bedeutet das, dass Sie sich gleich zu Beginn Ihres inhaltsanalytisches Projekts intensiv mit dem Forschungsstand auseinandersetzen sollten und klären sollten, wie zentrale Konzepte in früheren Studien definiert und gemessen wurden.
- Erstellung des Kategoriensystems: Wählen Sie deduktiv aus der Theorie (Schritt 1) oder induktiv aus dem Material Merkmale zur Erhebung aus, aber in jedem Fall sollten Sie prüfen, dass Sie auf Basis der gewählten Kategorien Ihre Forschungsfrage beantworten können.
- Erweiterung des Kategoriensystems zu einem Codebuch: Sie recherchieren, ob Sie bereits existierende, getestete Codebücher zu den Sie interessierenden Merkmalen finden können (z.B. in Repositories, Papern zum Thema oder auf den Webseiten von einschlägigen Forschenden; die wohl am schnellsten zugängliche und am besten sortierte Quelle ist die DOCA-Database: https://www.hope.uzh.ch/doca), um ihre Kategorien zu operationalisieren, also für Codierer:innen messbar zu machen. Wenn Ihnen aus einer induktiven Sichtung des Materials bereits Ankerbeispiele bekannt sind, können Sie auch diese notieren.
- Pretest-Codierung: In einer ersten Testphase werden die Kategorien an einem kleinen Teil des Untersuchungsmaterials erstmalig ausprobiert. Ziel ist es, zu überprüfen, ob die Kategorien in der Praxis funktionieren oder ob sie angepasst werden müssen. Hier wird auch getestet, ob die Kategorien zu breit oder zu eng gefasst sind.
- Feinjustierung und Verbesserung: Nach dem Pretest werden die Kategorien gegebenenfalls spezifiziert, differenziert oder zusammengefasst. Es kann notwendig sein, bestimmte Kategorien aufzuspalten oder neue Kategorien hinzuzufügen, um alle relevanten Aspekte des Materials abzudecken. Sicherlich werden Sie auch (neue) Ankerbeispiele in Ihr Codebuch aufnehmen müssen.
- Finalisierung: Sobald das Kategoriensystem mehrfach erprobt und angepasst wurde, wird es finalisiert.
Codierung von Texten
Codierung von Texten in Excel
Texte können manuell in Excel codiert und als CSV- oder XLSX- Datei gespeichert werden. Bei der Erstellung einer Tabelle sollten Sie Spalten für jede Variable in Ihrem Codebuch definieren. Lassen Sie uns das an dem vorherigen Beispiel mit den Codierungen aus fbposts schauen:
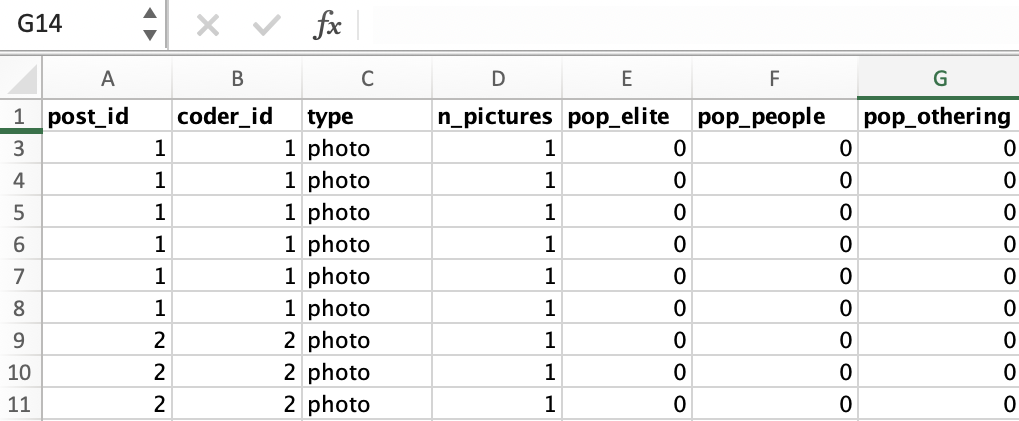
Nachdem Sie alle Texte codiert haben, können Sie diese speichern und in R für die weitere statistische Analyse mit der read.csv/read.xlsx einlesen.
Befehl:
# Einlesen einer CSV-Datei in R
library(tidyverse)
data <- read.csv("path/to/your/file.csv")
data %>% head()Codierung von Texten mit R
handcodeR
handcodeR (Isermann, 2023) ist ein Paket für R, das speziell für die manuelle Codierung von Texten entwickelt wurde. Es ermöglicht Ihnen, Ihre Textdaten strukturiert zu codieren und diese Codierungen direkt in einer einheitlichen Umgebung zu verwalten und zu analysieren. Um das Paket handcodeR zu installieren, verwenden Sie:
Befehl:
install.packages("handcodeR", force = TRUE)Die Hauptfunktion des Pakets is handcode(). Diese Funktion nimmt entweder einen Vektor von Texten und bis zu sechs benannte Zeichenvektoren mit Klassifikationskategorien oder ein bereits durch handcode() initialisiertes Dataframe als Eingabe. Die Funktion ermöglicht es Benutzer:innen, Texte mithilfe der vordefinierten Kategorien in einer interaktiven App zu annotieren und gibt ein Dataframe der Texte mit den annotierten Anmerkungen zurück.
Um die Nutzung von handcodeR zu demonstrieren, erstellen wir einen Beispiel-Post auf Facebook und codieren diesen mit den Funktionen des Pakets. Dabei orientieren wir uns an den Kategorien vom fbposts-Datensatz.
Befehl:
# Beispiel-Post
post_text <- c(
"Politicians must be held accountable for their actions. It’s time to address how economic elites are exploiting the system for their own benefit, manipulating the truth through media to serve their interests. We must protect our cultural heritage from these external threats and recognize that the public administration is failing to serve the people. Our voices matter, and it’s time for change!"
)Wir teilen den Post in einzelne Sätze auf, um die Codierung zu erleichtern. Dies wird durch die Funktion str_split aus dem Paket stringr erreicht.
# Aufteilen des Posts in einzelne Sätze
# install.packages("stringr") # nur das erste Mal nötig
library(stringr)
sentences_post <- unlist(str_split(post_text, pattern = "(?<=(?<!Mr)[\\.!?])\\s"))str_split() teilt den Text basierend auf Satzendezeichen (. oder ! oder ?), gefolgt von einem Leerzeichen, während unlist() verwendet wird, um die Liste der Sätze in einen einfachen Vektor zu konvertieren.
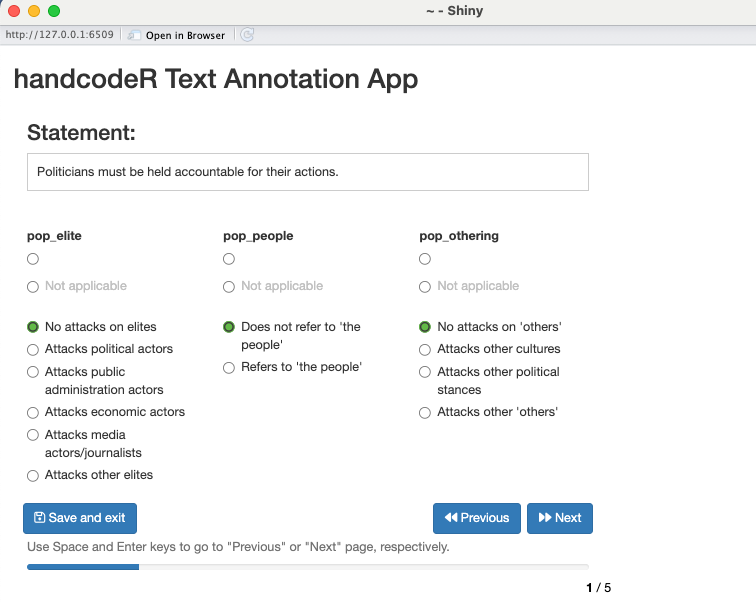
Wir verwenden die Funktion handcode(), um die Sätze des Posts zu codieren. Die Codierung basiert auf den Variablen pop_elite, pop_poeple und pop_othering.
Befehl:
# Codierung erstellen
annotated <- handcode(data = post_texts,
pop_elite = c("No attacks on elites", "Attacks political actors", "Attacks public administration actors", "Attacks economic actors", "Attacks media actors/journalists", "Attacks other elites"),
pop_people = c("Does not refer to 'the people'", "Refers to 'the people'"),
pop_othering = c("No attacks on 'others'", "Attacks other cultures", "Attacks other political stances", "Attacks other 'others'"))Ausgabe:
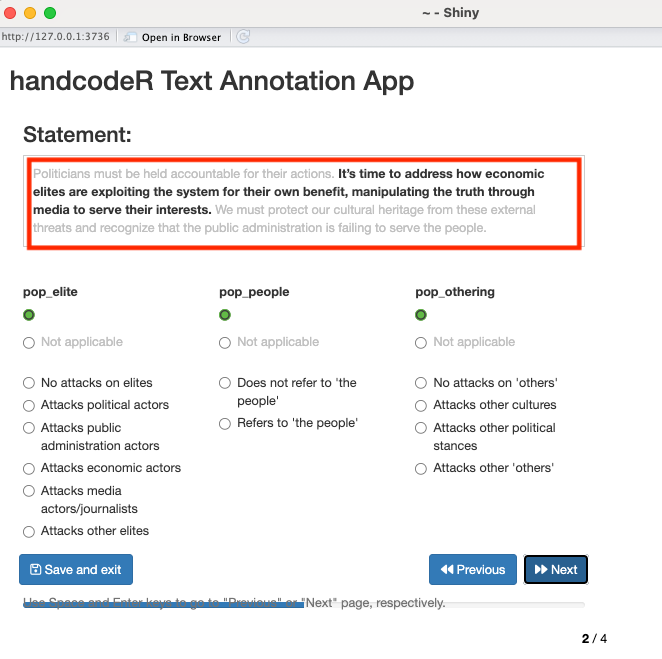
Zusätzlich können wir die Option context = TRUE verwenden, um den aktuellen Satz zusammen mit den vorhergehenden und nachfolgenden Sätzen für ein kontextuelles Verständnis anzuzeigen.
Befehl:
annotated <- handcode(data = sentences_post,
pop_elite = c("No attacks on elites", "Attacks political actors", "Attacks public administration actors", "Attacks economic actors", "Attacks media actors/journalists", "Attacks other elites"),
pop_people = c("Does not refer to 'the people'", "Refers to 'the people'"),
pop_othering = c("No attacks on 'others'", "Attacks other cultures", "Attacks other political stances", "Attacks other 'others'"),
context = TRUE)Ausgabe:
Sie können den Annotationsprozess jederzeit stoppen, indem Sie auf „Save and exit“ klicken. Danach wird die App geschlossen und die Funktion gibt einen Dataframe mit Ihren Texten und Anmerkungen zurück.
Ausgabe:

Um den Annotationsprozess später wieder aufzunehmen, verwenden Sie den zurückgegebenen Dataframe der letzten Ausführung von handcode() als Eingabe für einen neuen handcode()-Befehl. Standardmäßig setzt die Funktion die Annotation beim ersten noch nicht annotierten Text fort.
Befehl:
annotated <- handcode(data = annotated,
context = TRUE)Ausgabe:
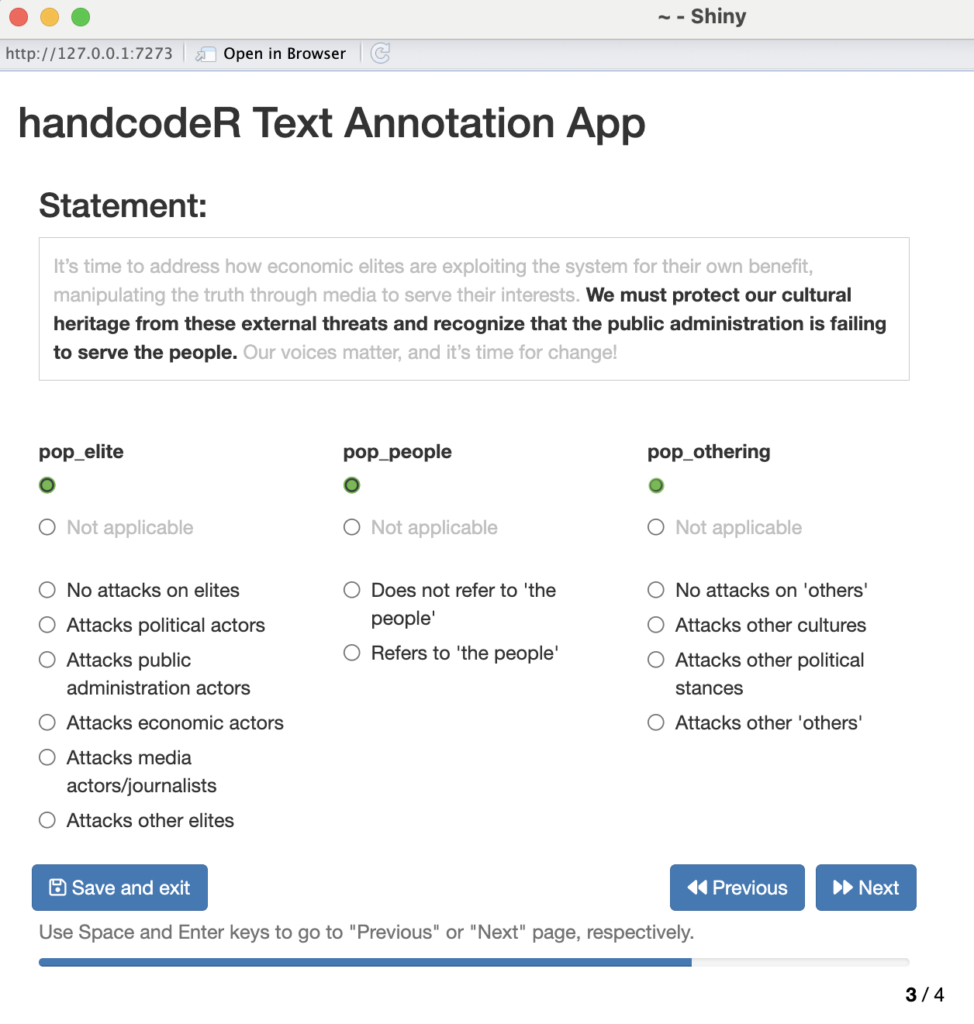
Um den Klassifizierungsprozess noch mehr zu vereinfachen, nutzt handcode()die Tastenkombinationen: Leertaste für „Zurück“ und Enter für „Weiter“. Bereits codierte Zeilen zeigen die vorherige Codierung an, während neue Zeilen leer bleiben. Erreicht man die letzte Zeile, speichert die „Next“-Taste automatisch die Daten und schließt die App.
Erweiterte Optionen
Standardmäßig beginnt handcode()die Codierung bei der ersten Zeile in den Eingabedaten, die noch nicht annotiert wurde. Mit der Option start können Sie jedoch festlegen, ab welcher Beobachtung der Codierungsprozess beginnen soll, zum Beispiel ab der dritten Zeile.
Befehl:
annotated <- handcode(data = sentences_post,
pop_elite = c("No attacks on elites", "Attacks political actors", "Attacks public administration actors", "Attacks economic actors", "Attacks media actors/journalists", "Attacks other elites"),
pop_people = c("Does not refer to 'the people'", "Refers to 'the people'"),
pop_othering = c("No attacks on 'others'", "Attacks other cultures", "Attacks other political stances", "Attacks other 'others'"),
start = 3)Ausgabe:
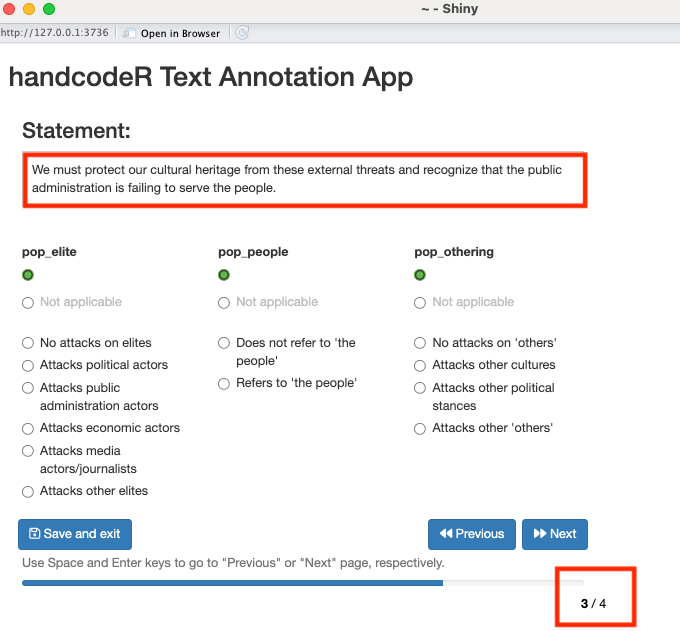
Falls sich nicht annotierte Zeilen zwischen bereits kodierten Zeilen befinden, können Sie start = "all empty" verwenden, um alle noch nicht kodierten Zeilen in der Reihenfolge, in der sie erscheinen, zu annotieren.
Befehl:
annotated <- handcode(data = sentences_post,
pop_elite = c("No attacks on elites", "Attacks political actors", "Attacks public administration actors", "Attacks economic actors", "Attacks media actors/journalists", "Attacks other elites"),
pop_people = c("Does not refer to 'the people'", "Refers to 'the people'"),
pop_othering = c("No attacks on 'others'", "Attacks other cultures", "Attacks other political stances", "Attacks other 'others'"),
start = "all_empty")Ausgabe:
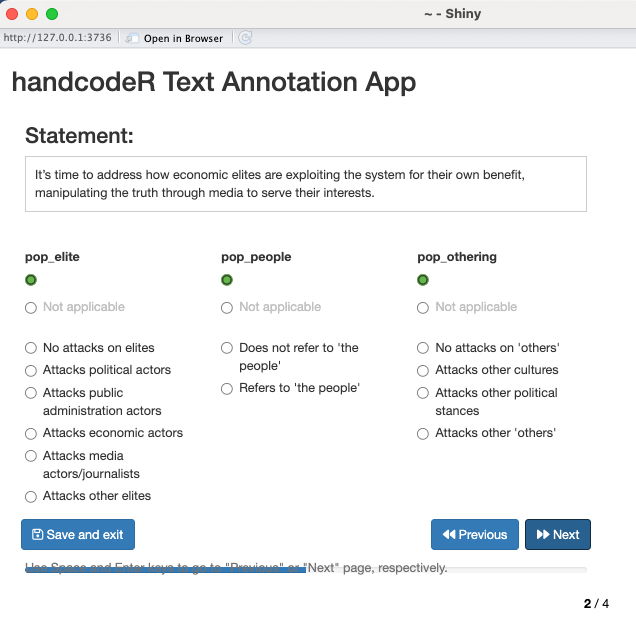
Es kann Situationen geben, in denen es sinnvoll ist, Texte in zufälliger Reihenfolge anzuzeigen, um sicherzustellen, dass der Kontext eines Textes innerhalb des größeren Textkörpers die Annotationen nicht beeinflusst. Um die Anzeigereihenfolge der Texte zu randomisieren, können Sie die Option randomize = TRUE verwenden. Dies hat jedoch keinen Einfluss auf die Reihenfolge, in der die Texte im finalen Output sortiert werden.
Befehl:
annotated <- handcode(data = sentences_post,
pop_elite = c("No attacks on elites", "Attacks political actors", "Attacks public administration actors", "Attacks economic actors", "Attacks media actors/journalists", "Attacks other elites"),
pop_people = c("Does not refer to 'the people'", "Refers to 'the people'"),
pop_othering = c("No attacks on 'others'", "Attacks other cultures", "Attacks other political stances", "Attacks other 'others'"),
randomize = TRUE)Ausgabe:

Standardmäßig zeigt handcode() die fehlende Kategorie „Not applicable“ an. Wenn Sie eine andere oder mehrere fehlende Kategorien anzeigen möchten, können Sie einen Zeichenvektor mit den gewünschten Kategorien angeben. Die fehlende Kategorien werden automatisch in Grau dargestellt.
Befehl:
annotated <- handcode(data = sentences_post,
pop_elite = c("No attacks on elites", "Attacks political actors", "Attacks public administration actors", "Attacks economic actors", "Attacks media actors/journalists", "Attacks other elites"),
pop_people = c("Does not refer to 'the people'", "Refers to 'the people'"),
pop_othering = c("No attacks on 'others'", "Attacks other cultures", "Attacks other political stances", "Attacks other 'others'"),
missing = c("Trifft nicht zu", "Unentschieden"))Ausgabe:

In der R-Ausgabe werden die fehlende Kategorien mit führenden und nachfolgenden Unterstrichen (_) gekennzeichnet:
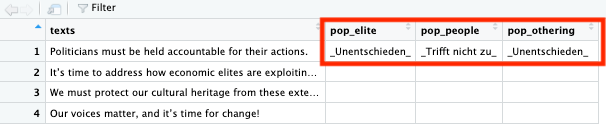
Codierung von Texten mit SoSci Survey
Eine Alternative zur Codierung mit handcodeR oder Excel ist die Nutzung von SoSci Survey, die durch die Erstellung einer Selbstbefragung auch für Inhaltsanalysen verwendet werden kann. Die Fragen und Kategorien, die Sie erstellen und danach beantworten, orientieren sich nochmals an Ihrer zentralen Forschungsfrage.
SoSci Survey bietet den Vorteil, dass Sie umfangreiche Definitionen und Ankerbeispiele auf derselben Seite platzieren können, was den Codierungsprozess erheblich erleichtert. Zudem ist die Filterführung sehr intuitiv, insbesondere wenn die Codierung einer Kategorie das Nicht-Codieren anderer Kategorien nach sich zieht.
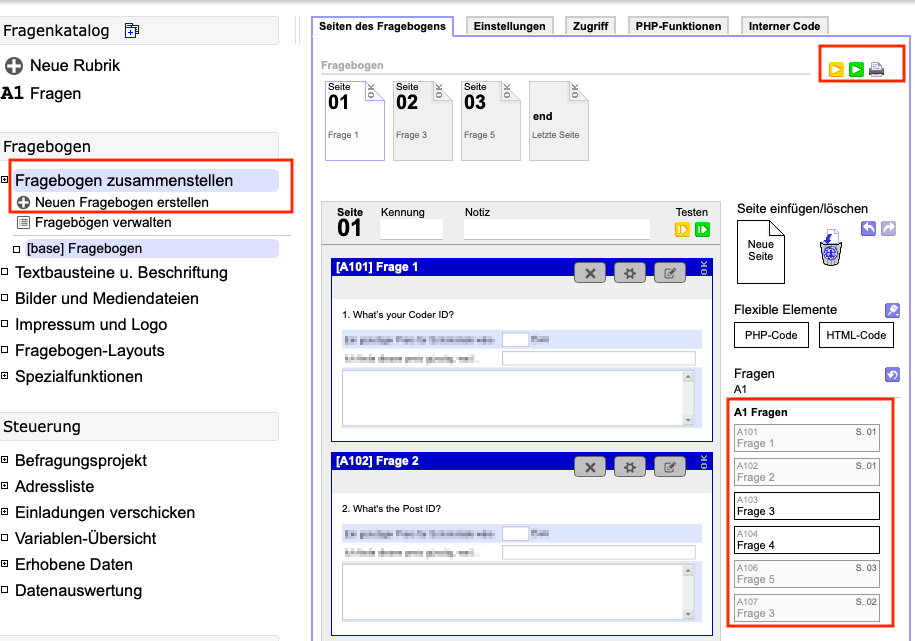
Sie können eine Selbstbefragung gestalten, indem Sie im Menü links oben unter “Fragenkatalog” auf “Rubriken” klicken, um neue Fragen zu erstellen und diese inhaltlich zu ordnen:

Für Antwortmöglichkeiten haben Sie verschiedene Optionen wie z.B. Auswahlfragen, Texteingaben, Bewertungen usw. Sie können auch detaillierte Beschreibungen der Kategorien einfügen, um den Codierern klare Anweisungen zu geben:
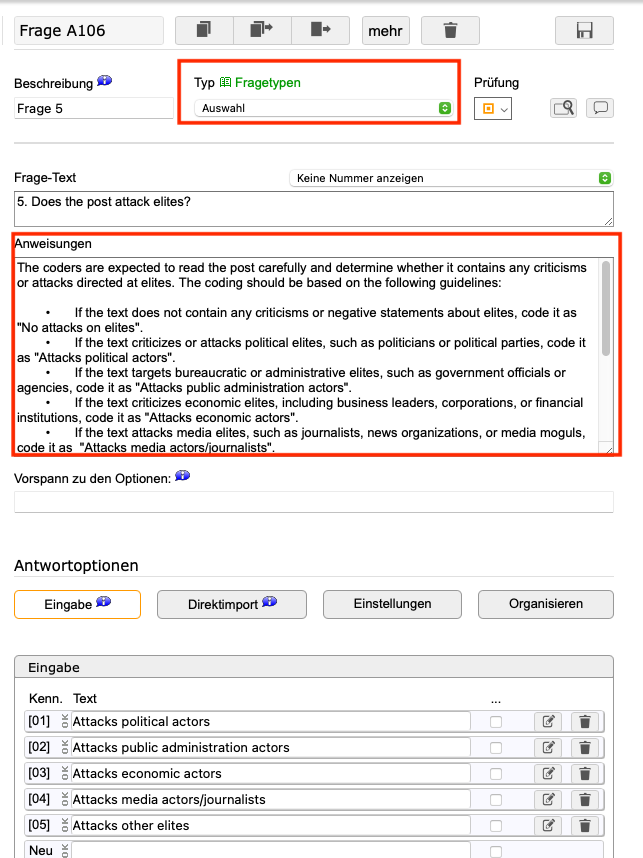
Danach gehen Sie auf “Fragebogen zusammenlegen”, wo Sie Ihre Fragen anordnen und ihre Darstellung in der Vorschau überprüfen können:
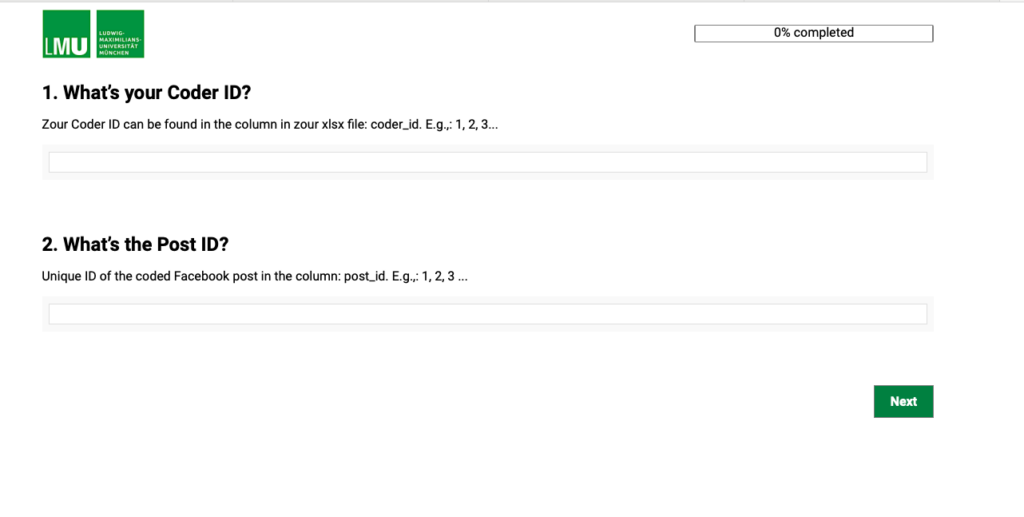
Vorschau-Fenster:
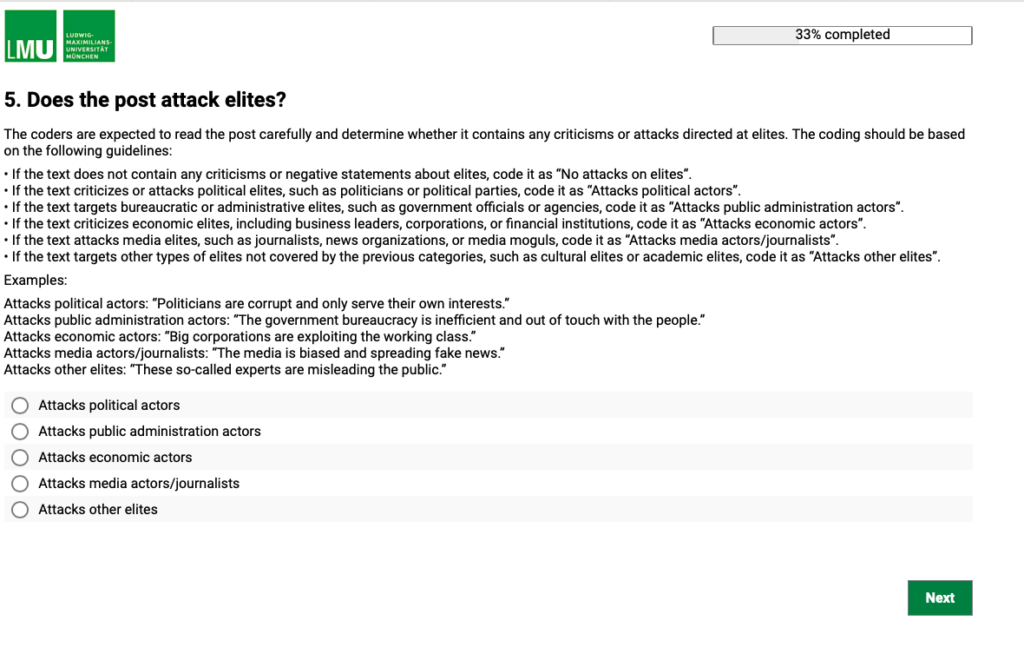
Im Vergleich zu handcodeR ist jedoch ein Nachteil, dass die zu annotierenden Texte in SoSci Survey nicht permanent sichtbar sind. Daher kann es hilfreich sein, den Text vor Beginn der Codierung zu kopieren, um am Ende noch einmal zu überprüfen, ob den richtigen Text mit der richtigen ID analysiert wurde. Dazu können Sie eine entsprechende Frage/Kategorie hinzufügen:
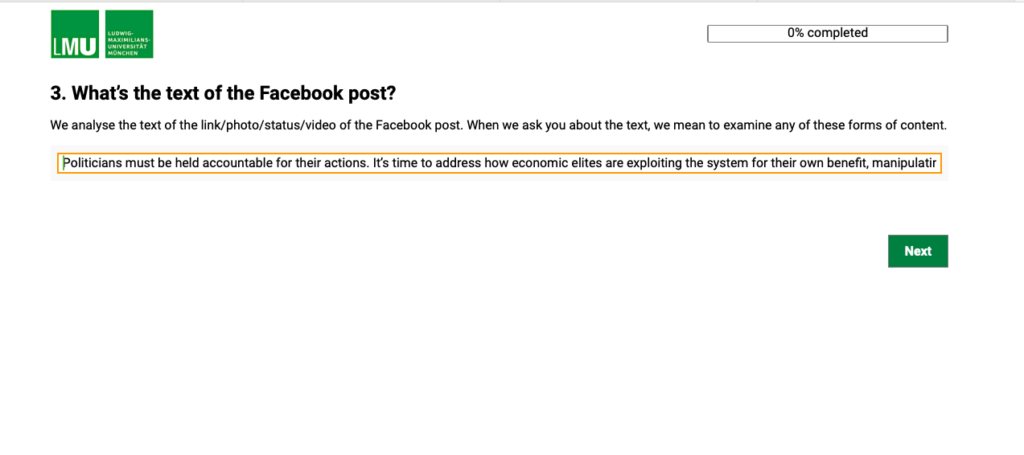
Weitere Informationen zur Erstellung von Fragebögen finden Sie auf der Website von SoSci Survey.
Berechnung der Intercoderreliabilität mit R
Nachdem Sie in den Pretest-Runden den Codierprozess abgeschlossen haben, ist es wichtig, die Intercoderreliabilität zu berechnen, um die Übereinstimmung zwischen verschiedenen Codierer:innen zu bewerten. Wir haben bereits ein existierendes, umfangreiches Kompendium zum Thema. Hier deswegen nur eine oberflächliche Betrachtung.
Befehl:
# Laden des Pakets tidycomm
library(tidycomm)
# Laden des fbposts-Datensatzes
fbposts <- tidycomm::fbposts
# Berechnung der Intercoderreliabilität
fbposts %>% test_icr(post_id, coder_id)Ausgabe:
# A tibble: 5 × 8
Variable n_Units n_Coders n_Categories Level Agreement Holstis_CR Krippendorffs_Alpha
* <chr> <int> <int> <int> <chr> <dbl> <dbl> <dbl>
1 type 45 6 4 nominal 1 1 1
2 n_pictures 45 6 7 nominal 0.822 0.930 0.880
3 pop_elite 45 6 6 nominal 0.733 0.861 0.339
4 pop_people 45 6 2 nominal 0.778 0.916 0.287
5 pop_othering 45 6 4 nominal 0.867 0.945 0.566Die Kennzahlen geben Aufschluss darüber, wie konsistent die Codierer:innen die Daten kodiert haben. Hohe Werte bei Agreement, Holsti’s CR und Krippendorff’s Alpha deuten auf eine hohe Übereinstimmung und damit auf eine hohe Reliabilität der Codierungen hin. Hier ist ein Beispielbericht nach Kategorien:
„Die Intercoderreliabilität wurde für fünf Variablen getestet, indem 45 Facebook-Posts von sechs Codierer:innen analysiert wurden. Für die formale Kategorie des Typs des Facebook-Beitrags wurde ein perfektes Krippendorffs Alpha von eins erreicht. Ebenso wurde für die Anzahl der dem Beitrag angehängten Bilder eine zufriedenstellende Übereinstimmung erzielt (α = 0,880). Allerdings wurden für die Populismus-Indikatoren keine zufriedenstellenden Reliabilitätswerte erreicht (αelite=0,339; αpeople=0,287; αothering=0,566), was dazu führte, dass das Kategoriensystem in einem weiteren Schritt überarbeitet werden musste.“
Referenzen
Isermann, Lukas. (2023). handcodeR: Text annotation app. R package version 0.1.2. http://doi.org/10.5281/zenodo.8075100.
Rössler, P. (2017). Inhaltsanalyse (3. Auflage). Utb.
Lehrmaterialien
Einführung in die Inhaltsanalyse.
Einführung in Codebücher.